We hebben gezien hoe afbeeldingen matrices van getallen worden en hoe visuele features hiërarchisch geleerd kunnen worden. Maar één vraag blijft: welk soort neuraal netwerk werkt eigenlijk goed voor afbeeldingen?
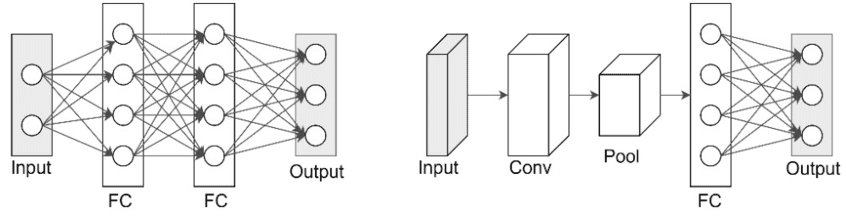
Als we een regulier feedforward-netwerk zouden proberen, zou elke pixel van een kleurenfoto (ongeveer 150.000 inputs) verbonden zijn met elke neuron in de eerste verborgen laag. Dat betekent miljoenen parameters—duur om te trainen en blind voor het feit dat nabije pixels belangrijker zijn dan verre.
De doorbraak kwam met Convolutional Neural Networks (CNN’s), die we kort hebben besproken in Hoofdstuk 4. In plaats van elke pixel onafhankelijk te behandelen, maken CNN’s gebruik van twee kernwaarheden: lokale patronen zijn betekenisvol en hetzelfde patroon kan overal in de afbeelding voorkomen.
Deze verschuiving transformeerde computer vision en legde de basis voor vrijwel elk modern beeld-AI-systeem.
Lokale Patronen En Gedeelde Detectoren
Visuele features zijn lokaal en herhalen zich in de afbeelding. Een rand, hoek of snorhaar ziet er hetzelfde uit linksboven als rechtsonder.
- In een volledig verbonden netwerk kan één neuron pixels combineren van een kattenoog, de bank erachter en de lucht in de hoek—nutteloos voor patroonherkenning.
- CNN’s verbinden neuronen in plaats daarvan met kleine stukjes pixels (zoals of ). Dit dwingt ruimtelijke samenhang af: filters leren lokale features zoals randen of texturen.
Nog een truc: parameter sharing. Ditzelfde filter scant de hele afbeelding. Een verticale-randdetector werkt ongeacht waar de rand verschijnt. Dit vermindert het aantal parameters drastisch en zorgt ervoor dat features locatie-onafhankelijk zijn.
Convolutie In Actie
Een filter (of kernel) is een kleine matrix met gewichten, neem dit voorbeeld:
Wanneer dit filter “glijdt” over de afbeelding, benadrukt het pixels op de hoeken en het midden van elk stukje. Regio’s die met deze structuur overeenkomen, produceren sterke activaties, terwijl gebieden zonder deze structuur waarden dicht bij nul teruggeven.
🏞️ Convolutie Sliding Voorbeeld:
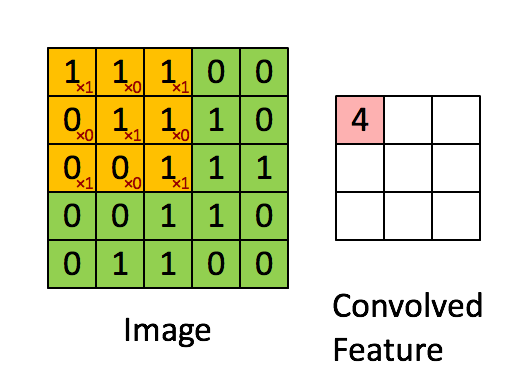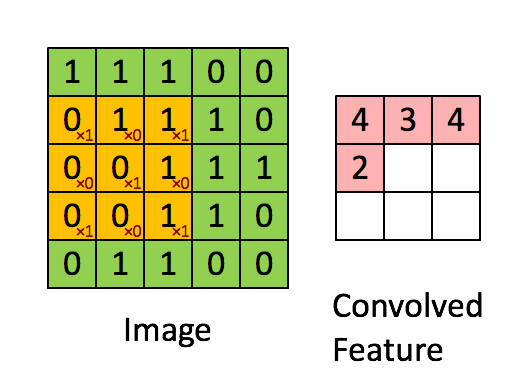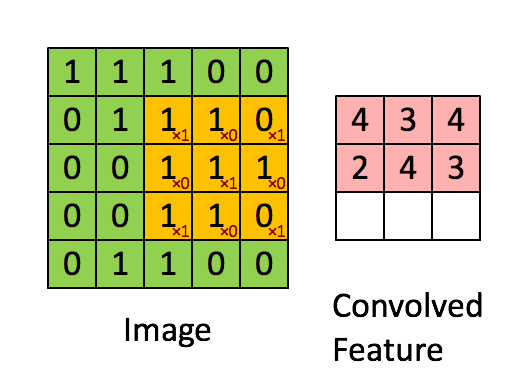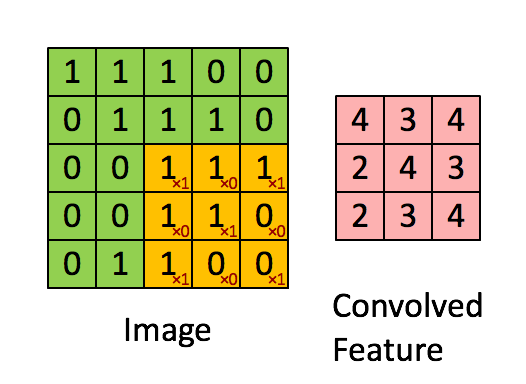
Elke convolutionele laag gebruikt tientallen—of honderden—filters, die elk een ander patroon detecteren (randen, krommen, texturen). De outputs vormen feature maps die laten zien waar die patronen verschijnen.
Door lagen te stapelen ontstaat een hiërarchie:
- Vroege lagen: randen, lijnen.
- Middenlagen: hoeken, krommen, texturen.
- Diepe lagen: objectdelen (gezichten, wielen, bladeren).
- Laatste lagen: volledige objecten.
Via dit gelaagde proces transformeren convolutionele netwerken ruwe pixels geleidelijk in rijke, hoog-niveau representaties die nauwkeurige objectherkenning mogelijk maken.
Pooling: Compact En Robuust
Na convolutie passen netwerken vaak een techniek toe die pooling heet, om de grootte van feature maps te verkleinen en robuustheid te vergroten.
- Max pooling (meest gebruikt): uit elk klein stukje (bijv. ) wordt de maximale waarde behouden.
- Dit halveert de dimensies, vermindert berekeningen en zorgt ervoor dat kleine verschuivingen in positie detectie niet tenietdoen.
- Een verticale rand die één pixel verschuift, activeert nog steeds dezelfde pooled-regio.
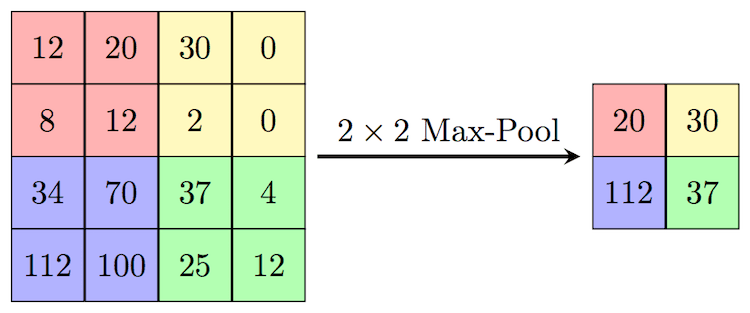
Pooling helpt CNN’s zich te richten op welke features aanwezig zijn, niet exact waar.
Een CNN Bouwen
Een typische CNN-architectuur ziet er zo uit:
- Input: RGB-afbeelding.
- Conv-laag: filters detecteren randen → feature maps.
- Pooling: verklein grootte, behoud sterkste activaties.
- Meer conv + pool-lagen: detecteer complexere patronen.
- Flatten: zet maps om in een 1D-vector.
- Volledig verbonden lagen: combineer features.
- Output: klassekansen (bijv. 10 categorieën voor cijfers).
Dit bouwt dezelfde architectuur die we eerder tegenkwamen:
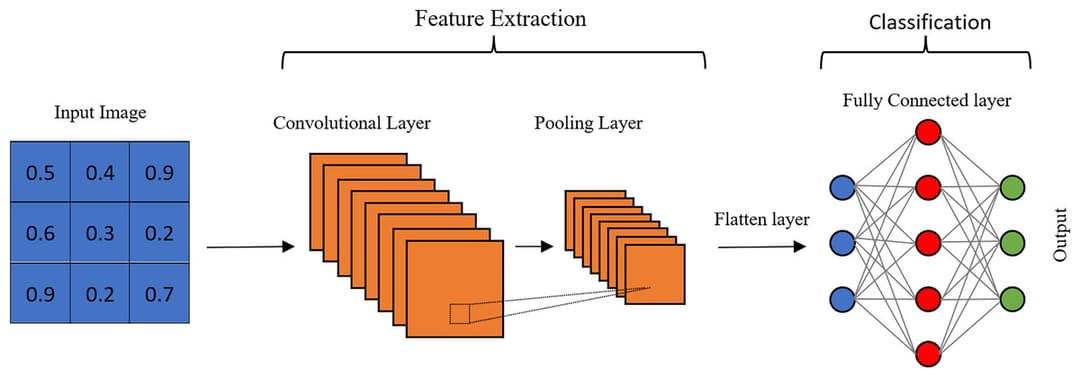
Hoe dieper we gaan, hoe abstracter de features worden—van pixels naar onderdelen naar objecten.
CNN’s Trainen
CNN’s trainen met backpropagation, net als andere neurale netwerken. Het verschil is dat ze in plaats van willekeurige gewichten voor elke pixel te leren, de kleine set filterwaarden leren die de meest bruikbare patronen vastleggen. Net zoals andere Deep Networks die we in eerdere hoofdstukken onderzochten, volgen CNN’s een trainingscyclus:
- Begin met willekeurige filters.
- Laat duizenden gelabelde afbeeldingen zien.
- Bereken voorspellingen en fouten.
- Backpropagate om filtergewichten aan te passen.
- Herhaal tot de filters automatisch betekenisvolle features detecteren.
Grote datasets zoals ImageNet (miljoenen afbeeldingen in 1.000+ categorieën) maakten het mogelijk dat CNN’s algemene features leerden die overdraagbaar zijn naar verschillende taken.
Waarom CNN’s Zo Goed Werken
CNN’s slagen omdat ze aansluiten bij hoe afbeeldingen werken:
- Ze behouden ruimtelijke structuur in plaats van die te flattenen.
- Ze leren hiërarchieën van features automatisch.
- Ze gebruiken minder parameters via weight sharing, waardoor ze efficiënt zijn.
- Ze gaan van nature om met translatie-invariantie—een kat is een kat, links of rechts.
- Pooling voegt robuustheid toe tegen verschuivingen, schaal en ruis.
Deze synergie van ontwerp en data maakte CNN’s de doorbraakarchitectuur voor visie.
Praktische CNN-Toepassingen
CNN’s hebben computer vision in talloze toepassingen gerevolutioneerd en behalen vaak superieure prestaties op specifieke taken.
🏞️ Beeldclassificatie: CNN’s categoriseren afbeeldingen in duizenden klassen, en drijven foto-apps, contentmoderatie en visuele zoekmachines aan.
🏥 Medische Beeldvorming: Ze detecteren kankers, breuken en ziekten in röntgenfoto’s, MRI’s en CT-scans—soms betrouwbaarder dan mensen.
🚗 Autonome Voertuigen: CNN’s verwerken camerabeelden om borden te lezen, voetgangers te zien en voertuigen in real time te volgen.
🏭 Productie: Gebruikt voor defectdetectie, assemblagecontroles en robotgeleiding, CNN’s vangen fouten die te subtiel zijn voor menselijke inspectie.
Beperkingen En Uitdagingen
Ondanks hun succes hebben CNN’s enkele belangrijke beperkingen waar onderzoekers nog steeds aan werken.
- Zware berekeningen: het trainen van diepe CNN’s is duur.
- Datahongerig: vereisen enorme gelabelde datasets.
- Kwetsbaar voor adversarial voorbeelden: kleine verstoringen kunnen ze misleiden.
- Domeingevoelig: een model getraind op webfoto’s kan falen bij medische scans.
- Bias: ondervertegenwoordigde groepen of contexten in trainingsdata kunnen leiden tot oneerlijke uitkomsten.
Deze beperkingen stimuleren nieuwere architecturen zoals Vision Transformers—maar CNN’s blijven de basis.
Belangrijkste Inzichten
Convolutionele Neurale Netwerken veranderden het spel door te respecteren wat afbeeldingen uniek maakt: lokale patronen, ruimtelijke relaties en herhalende features.
Door convolutie- en pooling-lagen te stapelen, leren CNN’s automatisch visuele hiërarchieën—van randen tot objecten—zonder handgemaakte regels. Ze voeden toepassingen in de gezondheidszorg, auto’s, fabrieken en meer.
Hoewel databehoefte, rekenkosten en kwetsbaarheden uitdagingen blijven, leverden CNN’s het blauwdruk voor moderne computer vision en inspireerden ze zelfs de architecturen die nu worden uitgebreid naar beeldgeneratie.