We hebben geleerd hoe diepe neurale netwerken in het algemeen werken—lagen stapelen om hiërarchische features te leren. Maar niet alle data is hetzelfde, en niet alle problemen vereisen dezelfde aanpak. Net zoals je geen hamer voor elke klus gebruikt, vragen verschillende soorten data om verschillende neurale netwerkarchitecturen.
De netwerken die beeldherkenning, taalvertaling en tijdreeksvoorspelling aandrijven gebruiken allemaal dezelfde fundamentele principes die we hebben geleerd—perceptrons, lagen en activatiefuncties—maar organiseren ze op gespecialiseerde manieren. Deze architecturale verschillen begrijpen helpt verklaren waarom ChatGPT uitblinkt in tekst maar moeite heeft met beelden, terwijl beeldherkenningssystemen objecten kunnen identificeren maar geen gesprekken kunnen voeren.
Laten we de belangrijkste soorten neurale netwerken verkennen en zien hoe elk geoptimaliseerd is voor specifieke soorten problemen.
Feedforward-Neurale Netwerken: De Basis
De netwerken die we tot nu toe hebben bestudeerd—perceptrons, MLP’s en diepe netwerken—zijn allemaal voorbeelden van Feedforward-Neurale Netwerken (FNNs). Informatie stroomt in één richting: van input via verborgen lagen naar output, zonder lussen of cycli.
- Informatie stroomt alleen voorwaarts (input → verborgen → output).
- Elke laag verwerkt informatie van de vorige laag.
- Geen geheugen van eerdere inputs of outputs.
- Het meest geschikt voor problemen waarbij inputs onafhankelijk zijn.
Enkele typische toepassingen van FNNs:
- Classificatie van tabeldata: Voorspellen van wanbetalingen op leningen, medische diagnoses.
- Eenvoudige regression: Huisprijzen, verkoopvoorspellingen.
- Patroonherkenning: Basisbeeldclassificatie, spamdetectie.
Feedforward-netwerken blinken uit wanneer elke input onafhankelijk verwerkt kan worden. Ze hebben echter moeite met sequentiële data waarbij context ertoe doet—zoals het begrijpen van zinnen of het voorspellen van aandelenkoersen op basis van historische trends.
Convolutionele Neurale Netwerken (CNNs): Meesters van Visuele Data
Wanneer je een foto uploadt naar sociale media en die automatisch je vrienden tagt, of wanneer de camera van je telefoon QR-codes herkent, zie je Convolutionele Neurale Netwerken (CNNs) in actie. CNNs zijn speciaal ontworpen om grid-achtige data te verwerken, vooral afbeeldingen.
In plaats van elke neuron te verbinden met elke input (zoals feedforward-netwerken), gebruiken CNNs "filters" of "kernels" die over de input schuiven en zoeken naar specifieke patronen zoals randen, texturen of vormen.
Hoe CNNs afbeeldingen verwerken:
- Convolutielagen: Toepassen van filters om features zoals randen en texturen te detecteren.
- Poolinglagen: Afbeeldingsgrootte verkleinen terwijl belangrijke informatie behouden blijft.
- Volledig verbonden lagen: Eindclassificaties maken op basis van gedetecteerde features.
🏞️ Voorbeeld CNN-Architectuur:
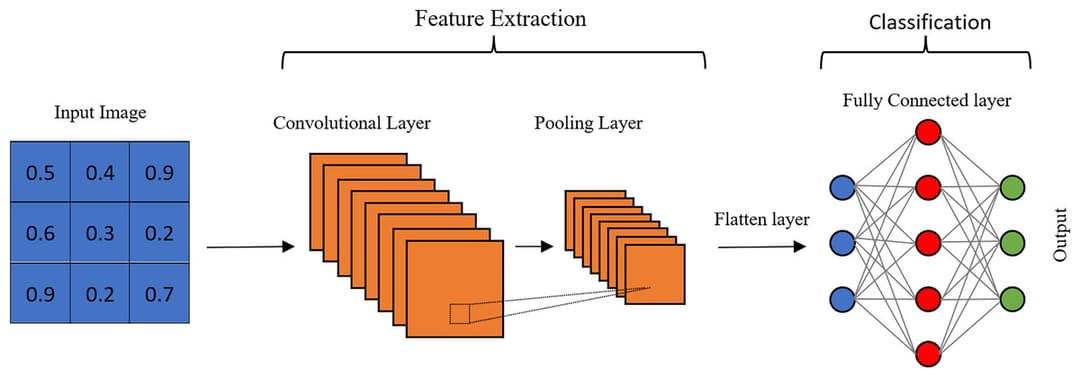
Toepassingen van CNNs buiten eenvoudige afbeeldingen:
- Medische beeldvorming: Röntgenanalyse, MRI-scans.
- Satellietbeelden: Milieumonitoring, stedelijke planning.
- Kwaliteitscontrole: Detectie van fabricagefouten.
Door deze gelaagde bewerkingen te combineren, kunnen CNNs automatisch betekenisvolle visuele features extraheren, waardoor ze de ruggengraat vormen van moderne computer vision-toepassingen.
Recurrente Neurale Netwerken (RNNs): Sequenties Begrijpen
Terwijl CNNs uitblinken met ruimtelijke data, pakken Recurrente Neurale Netwerken (RNNs) temporele of sequentiële data aan—informatie waarbij volgorde en context belangrijk zijn. RNNs hebben "geheugen" dat hen in staat stelt eerdere inputs te onthouden bij het verwerken van nieuwe.
In tegenstelling tot feedforward-netwerken die elke input onafhankelijk behandelen, behouden RNNs een "verborgen toestand" die informatie van eerdere tijdstappen meedraagt. Hierdoor kunnen ze context en afhankelijkheden over sequenties heen begrijpen.
💬 Voorbeeld RNN-Verwerking: Een RNN kan een zin zoals "The cat sat on the" als volgt verwerken:
- Verwerk "The" → Verborgen toestand slaat context op.
- Verwerk "cat" → Update context (zelfstandig naamwoord geïdentificeerd).
- Verwerk "sat" → Update context (werkwoord, verleden tijd).
- Verwerk "on" → Update context (voorzetsel).
- Verwerk "the" → Update context (ander zelfstandig naamwoord komt eraan).
- Voorspelling: "mat" (of "chair", "floor", enz.).
RNNs kunnen op verschillende manieren gebruikt worden:
- One-to-many: Beeldonderschrift (één afbeelding → reeks woorden).
- Many-to-one: Sentimentanalyse (reeks woorden → positief/negatief).
- Many-to-many: Taalvertaling (Engelse reeks → Franse reeks).
Een geavanceerdere en tot voor kort populaire RNN-variant is de Long Short-Term Memory (LSTM), die beter is in het onthouden van langetermijnafhankelijkheden:
- Taalmodellering: Voorspellen van volgende woorden in zinnen.
- Tijdreeksvoorspelling: Aandelenkoersen, weersvoorspelling.
- Spraakherkenning: Audio omzetten naar tekst.
Door sequentiële context vast te leggen via hun verborgen toestanden, legden RNNs de basis voor veel doorbraken in natural language processing en tijdreeksmodellering.
Transformers: De Moderne Revolutie
De architectuur achter ChatGPT, GPT-4 en de meeste moderne taalmodellen is geen RNN of CNN—het is een Transformer. Deze relatief recente innovatie (2017) heeft natural language processing gerevolutioneerd en breidt zich uit naar andere domeinen.
De kerninnovatie van deze architectuur: attention. In plaats van sequenties stap-voor-stap te verwerken zoals RNNs, gebruiken Transformers een "attention-mechanisme" dat zich tegelijkertijd op elk deel van de inputsequentie kan richten. Dit stelt ze in staat om langetermijnafhankelijkheden veel effectiever te begrijpen.
Bij het verwerken van het woord "it" in "The cat sat on the mat because it was comfortable" kan het attention-mechanisme "it" direct verbinden met "cat" zonder elk tussenliggend woord sequentieel te hoeven verwerken.
De Transformer-architectuur:
- Self-attention-lagen: Laten het model verschillende posities in een sequentie met elkaar relateren.
- Feedforward-netwerken: Verwerken de geattendeerde informatie.
- Positional encoding: Omdat er geen inherente sequentieverwerking is, wordt positie-informatie expliciet toegevoegd.
Transformers blinken om een aantal redenen uit:
- Parallelisatie: Kunnen volledige sequenties tegelijk verwerken (snellere training).
- Langetermijnafhankelijkheden: Directe verbindingen over elke afstand in de sequentie.
- Schaalbaarheid: Prestaties verbeteren dramatisch met meer data en parameters.
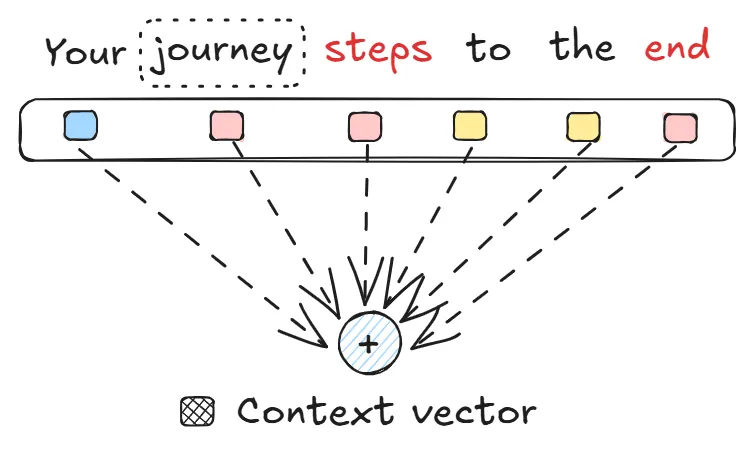
Transformers worden in allerlei vormen gebruikt, maar het mechanisme erachter blijft grotendeels hetzelfde. Enkele populaire AI-programma’s vandaag zijn allemaal gebaseerd op de architectuur:
- Large Language Models: GPT, ChatGPT, Claude.
- Machinevertaling: De moderne backend van Google Translate.
- Vision Transformers: Toepassen van attention op beeldpatches.
Met hun attention-gedreven ontwerp zijn Transformers de basis geworden van de AI van vandaag, en drijven ze state-of-the-art-systemen aan in taal, visie en daarbuiten.
Hybride Architecturen: Sterktes Combineren
Moderne AI-systemen combineren vaak meerdere architectuurtypes om hun respectieve sterktes te benutten:
CNN + RNN voor Video’s:
- CNNs extraheren features uit individuele frames.
- RNNs modelleren temporele relaties tussen frames.
- Resultaat: beter begrip van beweging en acties in video’s.
Transformer + CNN voor Visie:
- CNNs verwerken beeldpatches.
- Transformers modelleren relaties tussen patches.
- Resultaat: Vision Transformers die kunnen concurreren met traditionele CNNs.
Multi-Modal Modellen:
- Combineren tekst- en beeldverwerking.
- AI-systemen die afbeeldingen kunnen beschrijven of vragen over foto’s beantwoorden.
- Gebruik van verschillende architecturen voor verschillende inputtypen, en daarna combineren van resultaten.
Door complementaire architecturen te combineren, ontsluiten hybride modellen mogelijkheden die geen enkele benadering op zichzelf kan bereiken.
Belangrijkste Inzichten
Verschillende neurale netwerkarchitecturen zijn gespecialiseerde tools, geoptimaliseerd voor verschillende soorten data en problemen. Feedforward-netwerken bieden de basis om te begrijpen hoe lagen informatie sequentieel verwerken. CNNs blinken uit met ruimtelijke data zoals afbeeldingen door convolutieoperaties te gebruiken die lokale patronen detecteren en hiërarchische representaties opbouwen. RNNs behandelen sequentiële data door geheugen van eerdere inputs te behouden, waardoor ze ideaal zijn voor tijdreeksen en taal. Transformers revolutioneren sequentieverwerking door attention-mechanismen die direct relaties leggen tussen willekeurige delen van een sequentie.
Het begrijpen van deze architecturale verschillen helpt verklaren waarom bepaalde AI-systemen uitblinken in specifieke domeinen en helpt bij het kiezen van de juiste modellen voor verschillende toepassingen. Naarmate het veld zich ontwikkelt, combineren hybride architecturen steeds vaker de sterktes van verschillende benaderingen om complexe, multimodale problemen aan te pakken.