We've learned how deep neural networks work in general—stacking layers to learn hierarchical features. But not all data is the same, and not all problems require the same approach. Just as you wouldn't use a hammer for every construction job, different types of data call for different neural network architectures.
The networks powering image recognition, language translation, and time series prediction all use the same fundamental principles we've learned—perceptrons, layers, and activation functions—but organize them in specialized ways. Understanding these architectural differences helps explain why ChatGPT excels at text but struggles with images, while image recognition systems can identify objects but can't hold conversations.
Let's explore the main types of neural networks and see how each is optimized for specific kinds of problems.
Feedforward Neural Networks: The Foundation
The networks we've studied so far—perceptrons, MLPs, and deep networks—are all examples of Feedforward Neural Networks (FNNs). Information flows in one direction: from input through hidden layers to output, with no loops or cycles.
- Information flows forward only (input → hidden → output).
- Each layer processes information from the previous layer.
- No memory of previous inputs or outputs.
- Best suited for problems where inputs are independent.
Some typical applications of FNNs:
- Tabular data classification: Predicting loan defaults, medical diagnoses.
- Simple regression: House prices, sales forecasting.
- Pattern recognition: Basic image classification, spam detection.
Feedforward networks excel when each input can be processed independently. However, they struggle with sequential data where context matters—like understanding sentences or predicting stock prices based on historical trends.
Convolutional Neural Networks (CNNs): Masters of Visual Data
When you upload a photo to social media and it automatically tags your friends, or when your phone's camera recognizes QR codes, you're witnessing Convolutional Neural Networks (CNNs) in action. CNNs are specifically designed to process grid-like data, especially images.
Instead of connecting every neuron to every input (like feedforward networks), CNNs use "filters" or "kernels" that slide across the input, looking for specific patterns like edges, textures, or shapes.
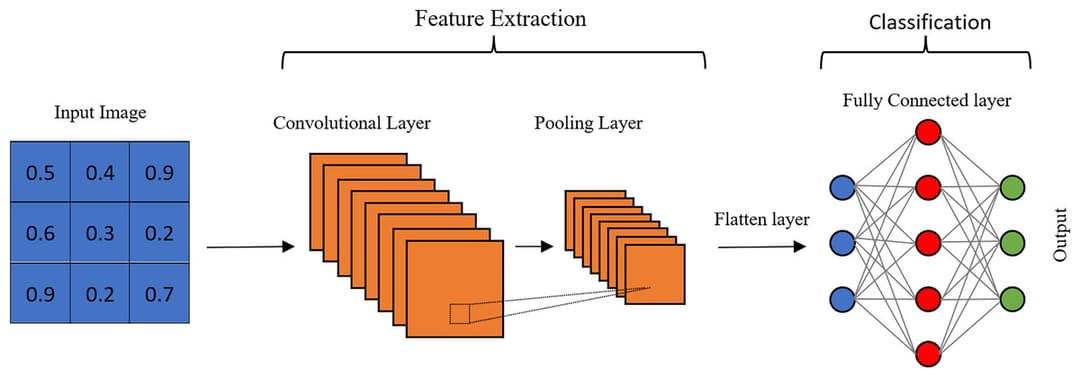
How CNNs process images:
- Convolution layers: Apply filters to detect features like edges and textures.
- Pooling layers: Reduce image size while keeping important information.
- Fully connected layers: Make final classifications based on detected features.
🏞️ CNN Architecture Example:
Applications of CNNs beyond simple images:
- Medical imaging: X-ray analysis, MRI scans.
- Satellite imagery: Environmental monitoring, urban planning.
- Quality control: Manufacturing defect detection.
By combining these layered operations, CNNs can automatically extract meaningful visual features, making them the backbone of modern computer vision applications.
Recurrent Neural Networks (RNNs): Understanding Sequences
While CNNs excel with spatial data, Recurrent Neural Networks (RNNs) tackle temporal or sequential data—information where order and context matter. RNNs have "memory" that allows them to remember previous inputs when processing new ones.
Unlike feedforward networks that treat each input independently, RNNs maintain a "hidden state" that carries information from previous time steps. This allows them to understand context and dependencies across sequences.
💬 RNN Processing Example: A RNN might process a sentence like "The cat sat on the" as follows:
- Process "The" → Hidden state stores context.
- Process "cat" → Updates context (noun identified).
- Process "sat" → Updates context (verb, past tense).
- Process "on" → Updates context (preposition).
- Process "the" → Updates context (another noun coming).
- Prediction: "mat" (or "chair", "floor", etc.).
RNNs can be used in several ways:
- One-to-many: Image captioning (one image → sequence of words).
- Many-to-one: Sentiment analysis (sequence of words → positive/negative).
- Many-to-many: Language translation (English sequence → French sequence).
A more advanced and, untill recently, popular advanced RNN is the Long Short-Term Memory (LSTM). Which is better at remembering long-term dependencies:
- Language modeling: Predicting next words in sentences.
- Time series forecasting: Stock prices, weather prediction.
- Speech recognition: Converting audio to text.
By capturing sequential context through their hidden states, RNNs laid the groundwork for many breakthroughs in natural language processing and time-series modeling.
Transformers: The Modern Revolution
The architecture behind ChatGPT, GPT-4, and most modern language models isn't an RNN or CNN—it's a Transformer. This relatively recent innovation (2017) has revolutionized natural language processing and is expanding into other domains.
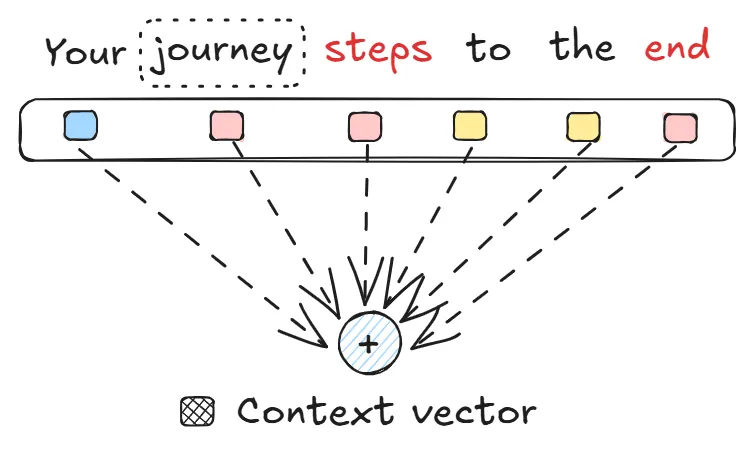
The key innovation of this architecture: attention. Instead of processing sequences step-by-step like RNNs, Transformers use an "attention mechanism" that can focus on any part of the input sequence simultaneously. This allows them to understand long-range dependencies much more effectively.
When processing the word "it" in "The cat sat on the mat because it was comfortable", the attention mechanism can directly connect "it" to "cat" without processing every word in between sequentially.
The Transformer architecture:
- Self-attention layers: Allow the model to relate different positions in a sequence.
- Feed-forward networks: Process the attended information.
- Positional encoding: Since there's no inherent sequence processing, position information is added explicitly.
Transformers excel for a number of reasons:
- Parallelization: Can process entire sequences simultaneously (faster training).
- Long-range dependencies: Direct connections across any distance in the sequence.
- Scalability: Performance improves dramatically with more data and parameters.
Transformers are widely used in all shapes and forms, but the mechanism behind them remains largely unchanged. Some popular AI programs today are all based on the architecture:
- Large Language Models: GPT, ChatGPT, Claude.
- Machine Translation: Google Translate's modern backend.
- Vision Transformers: Applying attention to image patches.
With their attention-driven design, Transformers have become the foundation of today’s AI, powering state-of-the-art systems across language, vision, and beyond.
Hybrid Architectures: Combining Strengths
Modern AI systems often combine multiple architecture types to leverage their respective strengths:
CNN + RNN for Videos:
- CNNs extract features from individual frames.
- RNNs model temporal relationships between frames.
- Resulting in better understanding of motion and action in videos.
Transformer + CNN for Vision:
- CNNs process image patches.
- Transformers model relationships between patches.
- Resulting in Vision Transformers that can compete with traditional CNNs.
Multi-Modal Models:
- Combine text and image processing.
- AI systems that can describe images or answer questions about photos.
- Use different architectures for different input types, then combine results.
By blending complementary architectures, hybrid models unlock capabilities that no single approach could achieve on its own.
Final Takeaways
Different neural network architectures are specialized tools optimized for different types of data and problems. Feedforward networks provide the foundation for understanding how layers process information sequentially. CNNs excel at spatial data like images by using convolution operations that detect local patterns and build hierarchical representations. RNNs handle sequential data by maintaining memory of previous inputs, making them ideal for time series and language tasks. Transformers revolutionize sequence processing through attention mechanisms that can relate any parts of a sequence directly.
Understanding these architectural differences helps explain why certain AI systems excel in specific domains and guides the choice of appropriate models for different applications. As the field evolves, hybrid architectures increasingly combine the strengths of different approaches to tackle complex, multi-modal problems.