Niet alle machine learning werkt op dezelfde manier. Net zoals er verschillende manieren zijn om mensen iets te leren—sommigen leren het best met stapsgewijze instructies, terwijl anderen liever ontdekken en patronen zelf afleiden—gebruiken AI-systemen verschillende leerstrategieën, afhankelijk van de situatie.
De twee belangrijkste benaderingen zijn supervised learning, waarbij we zowel vragen als juiste antwoorden geven zoals met flashcards, en unsupervised learning, waarbij de AI verborgen patronen ontdekt zonder dat we vertellen waar het naar moet zoeken. Het begrijpen van dit fundamentele onderscheid helpt je de juiste aanpak te kiezen voor verschillende problemen en maakt duidelijk waarom sommige AI-taken makkelijker zijn dan andere.
Supervised Learning: Leren Met Een Leraar
Supervised learning werkt precies als studeren met flashcards of oefenen met een tutor die je door problemen heen begeleidt. We laten de AI veel voorbeelden zien met zowel de input (de vraag) als de output (het juiste antwoord), en het leert inputs naar outputs te vertalen.
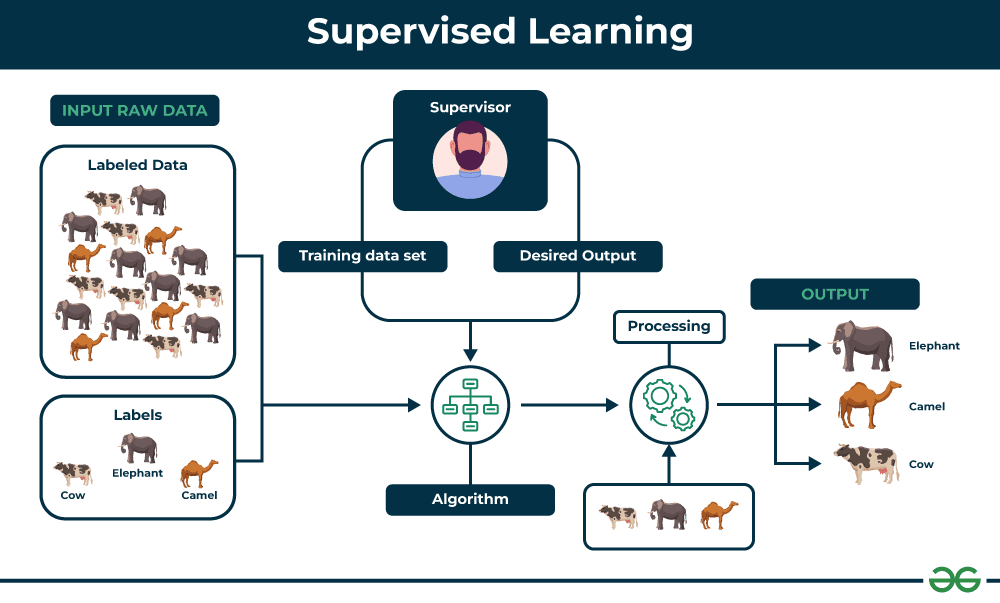
🏠 Voorbeeld Voorspellen Van Huizenprijzen: Laten we teruggaan naar ons huizenprijs-model. We geven een dataset waarin elk huis kenmerken heeft die we kunnen meten, en de daadwerkelijke verkoopprijs:
| Grootte (m²) | Locatiescore | Prijs (€) |
|---|---|---|
| 1200 | 8/10 | 250.000 |
| 1800 | 9/10 | 350.000 |
| 1500 | 6/10 | 200.000 |
De AI bestudeert deze voorbeelden en leert dat grotere huizen op betere locaties doorgaans meer kosten. Na duizenden voorbeelden kan het prijzen voorspellen van nieuwe huizen die het nog nooit heeft gezien.
Het Leerproces:
- Het model begint met voorspellingen doen zonder kennis.
- Het controleert hoe ver elke schatting afwijkt van het echte resultaat (het voorspelt €300.000 voor een huis dat verkocht is voor €250.000).
- Het verschil tussen de schatting en de echte waarde is de fout (€50.000).
- Het model past interne gewichten aan om toekomstige fouten te verkleinen, met behulp van de afgeleide.
- Deze cyclus gaat door totdat het model nauwkeurig genoeg is.
Veelvoorkomende Supervised Learning-Taken
Er zijn in principe twee grote supervised learning-taken:
- Classificatie: Dingen in categorieën indelen (spamdetectie, medische diagnose, beeldherkenning).
- Regressie: Numerieke waarden voorspellen (aandelenkoersen, verkoopprognoses, temperatuurvoorspelling).
Het grootste voordeel van supervised learning is de nauwkeurigheid, mits je goede gelabelde data hebt. Het nadeel is dat labels maken vaak enorm veel menselijk werk kost—stel je voor dat je miljoenen afbeeldingen of e-mails handmatig moet labelen.
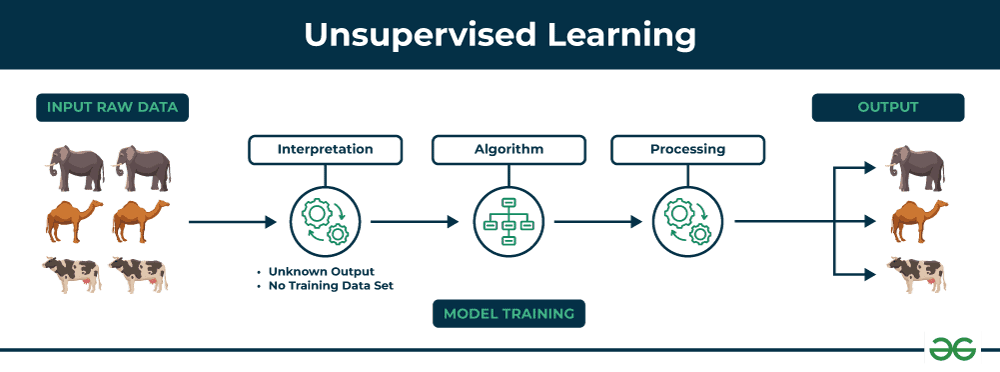
Unsupervised Learning: Verborgen Patronen Vinden
Unsupervised learning lijkt op het krijgen van een enorme stapel documenten in een vreemde taal met de opdracht ze op onderwerp te ordenen. Je kunt de inhoud niet lezen, maar je ziet patronen—sommige documenten zijn langer, sommige hebben vergelijkbare opmaak, sommige bevatten vergelijkbare symbolen. De AI doet iets soortgelijks met data.
👨🏼💼 Voorbeeld Klantsegmentatie: Een e-commercebedrijf wil zijn klanten beter begrijpen, maar weet niet vooraf welke soorten klanten er zijn. Ze verzamelen koopgedrag-data:
| Klant | Aankopen | Gem. Uitgaven (€) |
|---|---|---|
| Alice | 12 | 10 |
| Bob | 15 | 20 |
| Carol | 80 | 70 |
| Dave | 65 | 50 |
Hieronder hebben we de vier klanten uitgezet, samen met wat willekeurige andere klanten. Er lijkt duidelijk een patroon te zijn waarbij klanten zich groeperen (of clusteren) in bepaalde gebieden.
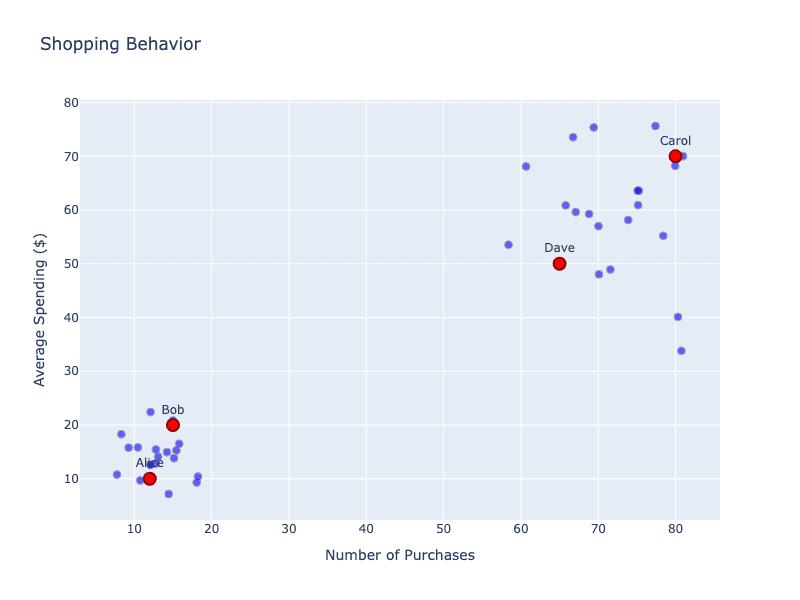
Het model ontdekt natuurlijke groeperingen zonder dat we vertellen waarnaar het moet zoeken: frequente lage uitgaven (Alice, Bob), incidentele grote uitgaven en power users (Carol, Dave). Deze inzichten helpen het bedrijf om marketingstrategieën af te stemmen op elk klanttype.
Veelvoorkomende Unsupervised Learning-Toepassingen
- Clustering: Marktsegmentatie, genanalyse, documentorganisatie.
- Anomaliedetectie: Fraudedetectie, netwerkbeveiliging, kwaliteitscontrole.
- Patroonontdekking: Aanbevelingssystemen, trendanalyse, verborgen verbanden.
Labels maken is duur en tijdrovend. Medische experts doen er maanden over om duizenden röntgenfoto’s te labelen. Security-analisten kunnen niet handmatig miljoenen transacties nakijken. Unsupervised learning laat AI waardevolle patronen vinden in ruwe data, vaak inzichten die mensen zouden missen of structuren waarvan we niet wisten dat ze bestonden.
De Juiste Aanpak Kiezen
De keuze tussen supervised en unsupervised learning hangt af van je doelen en beschikbare data.
Supervised Learning is ideaal wanneer:
- Je duidelijke vragen hebt om te beantwoorden (Zal deze transactie frauduleus zijn?).
- Historische gelabelde data beschikbaar is.
- Je nauwkeurige voorspellingen wilt voor nieuwe data.
- De kosten van fouten hoog zijn en precisie belangrijk is.
Unsupervised Learning werkt het best wanneer:
- Je data verkent zonder specifieke vragen.
- Labelen te duur of onmogelijk is.
- Je onverwachte patronen wilt ontdekken.
- Je de datastructuur wilt begrijpen voordat je voorspellende modellen bouwt.
Veel succesvolle AI-systemen combineren beide benaderingen. Een fraudedetectiesysteem kan beginnen met unsupervised learning om ongebruikelijke transactiepatronen te identificeren, en daarna supervised learning gebruiken om specifieke transacties te classificeren als frauduleus of legitiem op basis van experts.
Denk opnieuw aan de inspanning die nodig is om gelabelde datasets te maken: radiologen die maanden besteden aan het labelen van medische scans, taalkundigen die duizenden zinnen annoteren voor vertaalsystemen, of security-experts die transactiegeschiedenissen nakijken. Unsupervised learning biedt een manier om waarde uit data te halen zonder die enorme menselijke investering, al levert het meestal inzichten in plaats van directe antwoorden.
Belangrijkste Inzichten
Machine learning splitst zich op in twee fundamentele benaderingen, afhankelijk van de begeleiding tijdens training. Supervised learning gebruikt gelabelde voorbeelden om input-output-vertalingen te leren, ideaal voor voorspellingen en classificatie wanneer historische data met bekende uitkomsten beschikbaar is. Unsupervised learning ontdekt verborgen patronen in ongelabelde data, waardevol voor exploratie en het genereren van inzichten wanneer labelen onpraktisch is of wanneer je onverwachte structuren wilt blootleggen. Beide benaderingen zijn essentiële tools in de AI-gereedschapskist, en werken vaak samen om complexe problemen uit de echte wereld op te lossen die zowel patroonontdekking als nauwkeurige voorspelling vereisen.