Not all machine learning works the same way. Just like there are different approaches to teaching humans—some people learn best with step-by-step instruction while others prefer to explore and discover patterns on their own—AI systems use different learning strategies depending on the situation.
The two main approaches are supervised learning, where we provide both questions and correct answers like flashcards, and unsupervised learning, where the AI discovers hidden patterns without being told what to look for. Understanding this fundamental distinction helps you choose the right approach for different problems and appreciate why some AI tasks are easier than others.
Supervised Learning: Learning with a Teacher
Supervised learning works exactly like studying with flashcards or having a tutor guide you through practice problems. We show the AI many examples that include both the input (the question) and the output (the correct answer), and it learns to map inputs to outputs.
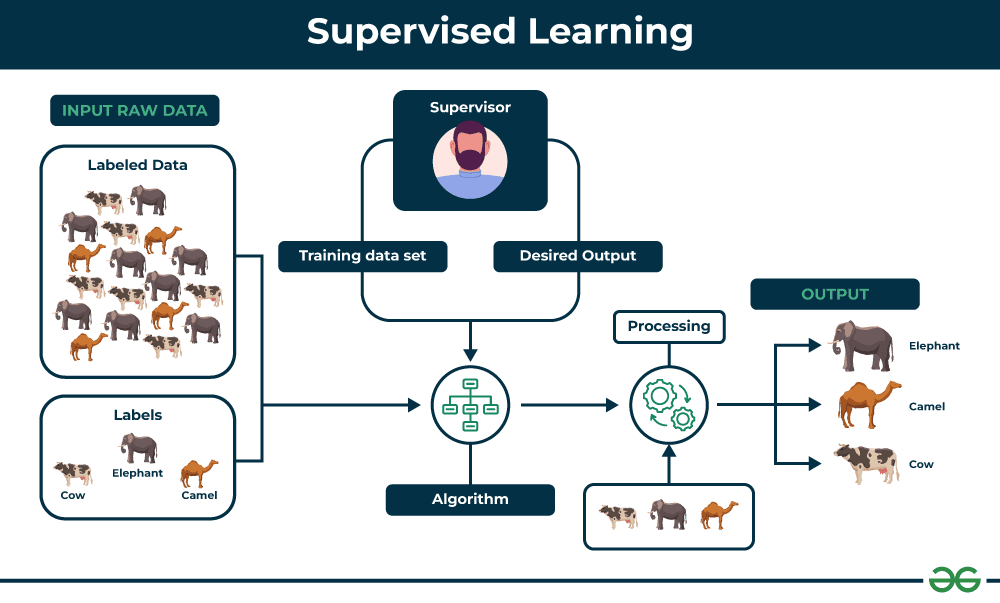
🏠 House Price Prediction Example: Let's return to our house prediction model. We provide a dataset where each house has both features we can measure and the actual sale price:
| Size (m²) | Location Score | Price (€) |
|---|---|---|
| 1200 | 0.8 | 250.000 |
| 1800 | 0.9 | 350.000 |
| 1500 | 0.6 | 200.000 |
The AI studies these examples and learns that larger houses in better locations typically cost more. After seeing thousands of such examples, it can predict prices for new houses it has never seen before.
The Learning Process:
- The model begins by predicting values without any knowledge.
- It checks how far off each guess is from the actual result (it predicts €300.000 for a house that actually sold for €250.000).
- The difference between the guess and the real value is the error (€50.000)
- The model adjusts its internal weights to reduce future errors, using the derivative.
- This cycle continues until the model becomes accurate enough to use.
Common Supervised Learning Tasks
There are basically two major supervised learning tasks that get implemented:
- Classification: Sorting things into categories (spam detection, medical diagnosis, image recognition).
- Regression: Predicting numerical values (stock prices, sales forecasting, temperature prediction).
The main advantage of supervised learning is its accuracy when you have good labeled data. The main disadvantage is that creating those labels often requires enormous human effort—imagine manually labeling millions of images or emails.
Unsupervised Learning: Finding Hidden Patterns
Unsupervised learning is like being given a huge pile of documents in a foreign language and asked to organize them by topic. You can't read the content, but you can notice patterns—some documents are longer, some have similar formatting, some contain similar symbols. The AI does something similar with data.
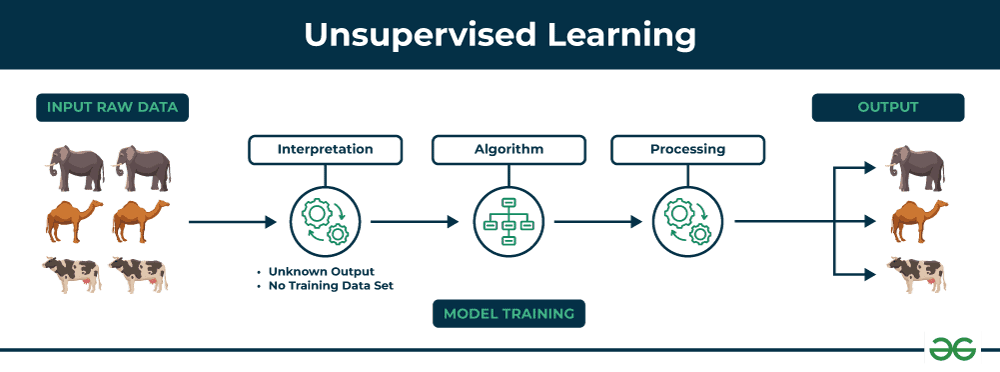
👨🏼💼 Customer Segmentation Example: An e-commerce company wants to understand their customers better, but they don't know in advance what types of customers they have. They collect shopping behavior data:
| Customer | Purchases | Avg Spending (€) |
|---|---|---|
| Alice | 12 | 10 |
| Bob | 15 | 20 |
| Carol | 80 | 70 |
| Dave | 65 | 50 |
Below we have plotted the four customers, as well as some other random customers. Clearly there seems to be a pattern here where customers group (or cluster) in certain areas.
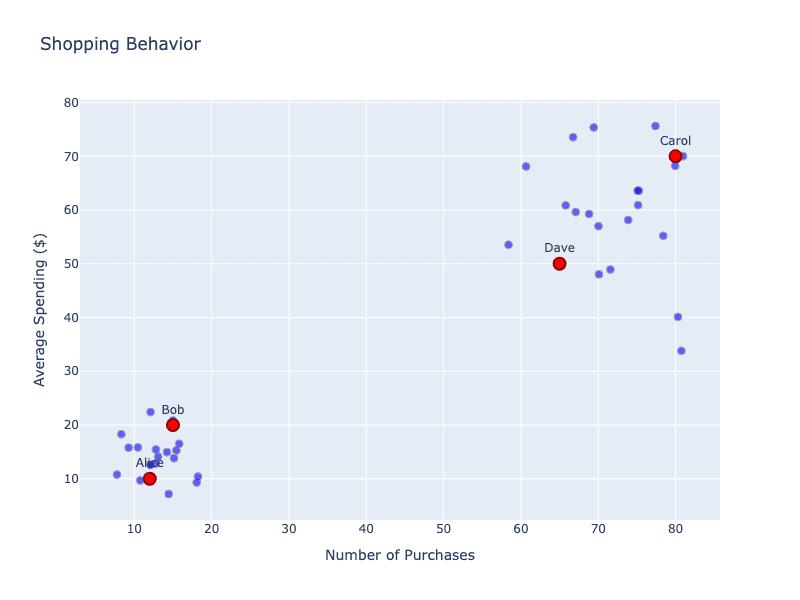
The model discovers natural groupings without being told what to look for: frequent low-spenders (Alice, Bob), occasional high-spenders, and power users (Carol, Dave). These insights help the company tailor marketing strategies for each customer type.
Some common Unsupervised Learning applications are:
- Clustering: Market segmentation, gene analysis, document organization.
- Anomaly Detection: Fraud detection, network security, quality control.
- Pattern Discovery: Recommendation systems, trend analysis, hidden relationships.
Labeling data is expensive and time-consuming. Medical experts need months to label thousands of X-rays. Security analysts can't manually review millions of transactions. Unsupervised learning lets AI find valuable patterns in raw data, often discovering insights that humans might miss or revealing structure we didn't know existed.
Choosing the Right Approach
The choice between supervised and unsupervised learning depends on your goals and available data.
Supervised Learning is ideal when:
- You have clear questions to answer (Will this transaction be fraudulent?).
- Historical labeled data is available.
- You need accurate predictions on new data.
- The cost of errors is high and precision matters.
Unsupervised Learning works best when:
- You're exploring data without specific questions.
- Labeling would be too expensive or impossible.
- You want to discover unexpected patterns.
- You need to understand data structure before building predictive models.
Many successful AI systems combine both approaches. A fraud detection system might start with unsupervised learning to identify unusual transaction patterns, then use supervised learning to classify specific transactions as fraudulent or legitimate based on expert reviews.
Consider again the effort required to create labeled datasets: radiologists spending months labeling medical scans, linguists annotating thousands of sentences for translation systems, or security experts reviewing transaction histories. Unsupervised learning offers a way to extract value from data without this massive human investment, though it typically provides insights rather than direct answers.
Final Takeaways
Machine learning splits into two fundamental approaches based on the type of guidance provided during training. Supervised learning uses labeled examples to learn input-output mappings, making it ideal for prediction and classification tasks when historical data with known outcomes is available. Unsupervised learning discovers hidden patterns in unlabeled data, making it valuable for exploration and insight generation when labeling is impractical or when you want to uncover unexpected structure. Both approaches are essential tools in the AI toolkit, often working together to solve complex real-world problems that require both pattern discovery and accurate prediction.