Elk reinforcement learning-systeem volgt dezelfde basisstructuur: een agent (de beslisser) die reageert met een environment (de wereld die het probeert te begrijpen of optimaliseren). Dit simpele framework is zeer veelzijdig en kan van alles beschrijven, van handelsalgoritmes en aanbevelingssystemen tot game-AI’s. In elk geval observeert de agent, beslist, handelt en leert van de uitkomst.
De elegantie zit in deze eenvoudige cyclus—herhaalde interacties leveren feedback die voortdurend het gedrag van de agent vormgeeft en verbetert.
De Agent: De Beslisser
De agent is het AI-systeem in het midden van reinforcement learning—de entiteit die waarneemt, beslist en handelt. In tegenstelling tot passieve systemen, neemt een agent actief beslissingen met gevolgen.
Denk aan de agent als een systeem met een aantal kerntaken:
- Waarnemen: De agent moet zijn huidige situatie begrijpen door informatie uit de omgeving te verwerken. Dat kan de stand van een spelbord zijn, sensorwaarnemingen van een robot, of gebruikersgedrag in een aanbevelingssysteem.
- Beslissen: Op basis van wat hij waarneemt, moet de agent bepalen welke actie hij vervolgens neemt. In het begin zijn die keuzes willekeurig, maar na verloop van tijd worden ze steeds geavanceerder.
- Leren: Na elke actie past de agent zijn kennis aan op basis van de resultaten. Hier ontstaat de "intelligentie": de geleidelijke verbetering van de kwaliteit van de beslissingen.
- Geheugen: De agent bewaart informatie over welke strategieën goed werken in verschillende situaties, en bouwt zo een ervaring op die toekomstige keuzes stuurt.
De mate van verfijning van een agent kan sterk verschillen. Eenvoudige agenten gebruiken misschien simpele regels of opzoektabellen, terwijl geavanceerde agenten diepe neurale netwerken inzetten om complexe sensorische input te verwerken en genuanceerde beslissingen te nemen.
De Environment: De Wereld om in te Navigeren
De environment (omgeving) omvat alles buiten de agent—de wereld die hij moet begrijpen, verkennen en beïnvloeden. Omgevingen kunnen fysiek zijn (zoals een magazijn voor een bezorgrobot), virtueel (zoals een videospel), of abstract (zoals een aandelenmarkt of de voorkeuren van gebruikers).
Environments hebben verschillende belangrijke eigenschappen:
- Toestandsruimte: Alle mogelijke situaties waarin de agent terecht kan komen. In schaken omvat dit elke mogelijke bordconfiguratie.
- Dynamiek: Sommige omgevingen zijn voorspelbaar (de regels van schaken veranderen nooit), terwijl andere stochastisch zijn (marktprijzen schommelen onvoorspelbaar).
- Observeerbaarheid: In sommige omgevingen kan de agent alles zien (zoals bij schaken). In andere is informatie gedeeltelijk of verborgen (zoals bij poker of navigatie in de echte wereld met beperkte sensoren).
- Complexiteit: Omgevingen variëren van eenvoudig (boter-kaas-en-eieren) tot extreem complex (het beheren van een supply chain of het begrijpen van natuurlijke taalgesprekken).
- Real-time eisen: Sommige omgevingen vragen om directe beslissingen, terwijl andere ruimte laten voor zorgvuldige overweging.
🚗 Voorbeeld Zelfrijdende Auto: Voor een autonome auto omvat de omgeving de wegcondities, het weer, andere voertuigen, voetgangers, verkeerslichten en talloze andere dynamische factoren. De agent (het rijsysteem) moet sensorinformatie verwerken om deze omgeving te begrijpen en rijbeslissingen te nemen die de auto veilig op de bestemming brengen.
States: Momentopnames van de Wereld
Een state beschrijft een specifieke situatie of configuratie waarin de agent zich kan bevinden. States bevatten alle relevante informatie die nodig is om op dat moment goede beslissingen te nemen.
De uitdaging bij het definiëren van states is het vinden van het juiste detailniveau:
- Te eenvoudig: Belangrijke informatie ontbreekt, waardoor de kwaliteit van beslissingen verslechtert. Een schaakprogramma dat alleen het aantal stukken telt maar de posities negeert, zou slechte zetten maken.
- Te complex: Onnodige details worden meegenomen, waardoor leren moeilijker en trager wordt. Een handelsalgoritme hoeft het weer niet te kennen, tenzij het in agrarische grondstoffen handelt.
- Precies goed: Alleen de essentiële informatie wordt vastgelegd die bepaalt welke acties waarschijnlijk succes opleveren.
Verschillende problemen vragen om verschillende representaties van states:
- Spellen: Bordposities, scores, resterende tijd.
- Robotica: Gewrichtsposities, sensorwaarnemingen, locaties van obstakels.
- Financiën: Prijstrends, marktindicatoren, samenstelling van portefeuilles.
- Aanbevelingssystemen: Gebruikersgeschiedenis, kenmerken van items, contextuele informatie.
De kwaliteit van de state-representatie heeft grote invloed op het succes van leren. Goed ontworpen states helpen agenten sneller te leren en betere beslissingen te nemen.
Actions: Wat de Agent Kan Doen
Actions vertegenwoordigen de set van keuzes die de agent op elk moment kan maken. Het ontwerp van de action space—welke actions mogelijk zijn en hoe ze gestructureerd zijn—heeft een grote invloed op hoe de agent leert en zich gedraagt.
Er bestaan verschillende soorten action spaces:
- Discrete actions: Een eindige set van afzonderlijke keuzes, zoals schaakzetten of knopindrukken in een videospel. Deze zijn vaak eenvoudiger om te leren, maar kunnen de flexibiliteit beperken.
- Continuous actions: Actions die gedefinieerd zijn door numerieke waarden, zoals stuurhoeken of biedbedragen. Deze bieden meer precisie, maar zijn moeilijker om effectief te leren.
- Composite actions: Complexe actions die opgebouwd zijn uit eenvoudigere componenten, zoals "ga naar de keuken en maak koffie", dat bestaat uit vele afzonderlijke bewegingen en beslissingen.
- Conditional actions: Actions die afhangen van de huidige state, zoals "als de prijs onder X daalt, verkoop Y aandelen".
🎮 Voorbeeld Game: In een racespel kan de agent discrete actions hebben (gas geven, remmen, linksaf slaan, rechtsaf slaan) of continuous actions (stuurhoek van -1 tot +1, gaspedaalstand van 0 tot 1). De continue aanpak biedt meer precieze controle, maar vraagt om geavanceerdere leeralgoritmes.
Rewards: Het Leersignaal
Rewards zijn het feedbackmechanisme dat leren in reinforcement learning-systemen aandrijft. Ze geven de agent informatie over hoe goed hij presteert en vormen het signaal om toekomstig gedrag te verbeteren.
Het ontwerpen van een goed rewardsysteem is zowel cruciaal als uitdagend:
- Onmiddellijke rewards: Directe feedback voor afzonderlijke actions, zoals punten voor het eten van stippen in Pac-Man of straffen voor botsingen bij autonoom rijden.
- Vertraagde rewards: Feedback die pas komt na een reeks actions, zoals winnen of verliezen in een schaakpartij. Deze zijn moeilijker om van te leren, maar vaak betekenisvoller.
- Sparse rewards: Situaties waarin feedback zeldzaam is, bijvoorbeeld alleen een reward bij het volledig afronden van een taak. Dit maakt leren lastiger, maar weerspiegelt veel realistische scenario’s.
- Dense rewards: Frequente feedback die leren directer stuurt, maar zorgvuldig moet worden ontworpen om onbedoeld gedrag te voorkomen.
💰 Voorbeeld Trading: Een handelsalgoritme kan rewards krijgen op basis van winst, maar dit vraagt om een doordacht ontwerp. Alleen de uiteindelijke winst belonen kan leiden tot overmatig risicogedrag. Rewards voor veelvuldige transacties kunnen juist tot overtrading leiden. De rewardstructuur bepaalt uiteindelijk welke strategie zich ontwikkelt.
Policies: De Strategie van de Agent
Een policy bepaalt hoe een agent in verschillende situaties actions kiest. Het is de strategie of beslisregel van de agent die states koppelt aan actions. Naarmate het leren vordert, evolueert de policy van willekeurige of eenvoudige regels naar verfijnde strategieën.
Policies kunnen verschillende vormen aannemen:
- Deterministische policies: Kiezen altijd dezelfde action in dezelfde state. Eenvoudig en voorspelbaar, maar mogelijk beperkt.
- Stochastische policies: Kiezen actions op basis van waarschijnlijkheden, wat ruimte geeft voor exploratie en aanpassing aan veranderende omstandigheden.
- Geparametriseerde policies: Policies die gedefinieerd worden door instelbare parameters (zoals de gewichten van een neuraal netwerk) die tijdens het leren geoptimaliseerd kunnen worden.
De policy is uiteindelijk waar het om draait—ze vertegenwoordigt het geleerde gedrag van de agent en bepaalt hoe goed deze presteert in de omgeving.
Alles Samenbrengen
Deze componenten werken samen in een voortdurende cyclus die leren en verbetering aandrijft:
- State-observatie: De agent neemt de huidige state van de omgeving waar.
- Actiekeuze: Met behulp van zijn huidige policy kiest de agent een action.
- Omgevingsreactie: De omgeving gaat over naar een nieuwe state en geeft een reward.
- Policy-update: De agent gebruikt deze ervaring om zijn policy te verbeteren.
- Herhaling van de cyclus: Het proces gaat verder vanuit de nieuwe state.
Dit framework geldt ongeacht het specifieke toepassingsdomein. Of het nu gaat om het trainen van een robot om te lopen, het optimaliseren van advertentieplaatsingen, of het ontwikkelen van spelstrategieën—dezelfde basisstructuur stuurt het leerproces.
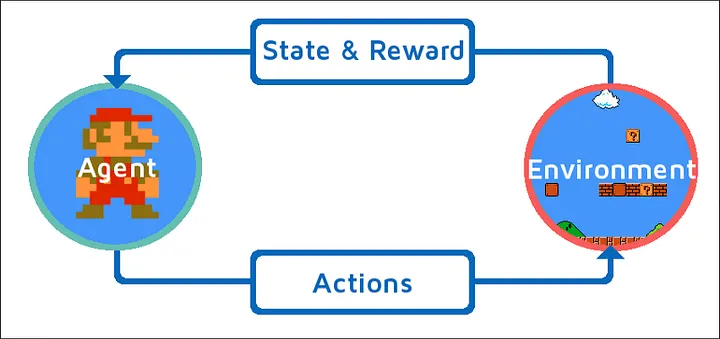
Deze structuur is universeel toepasbaar: van robots trainen tot advertenties optimaliseren en game-strategieën ontwikkelen.
Belangrijkste Inzichten
Het agent-omgeving framework vormt de conceptuele basis voor alle reinforcement learning-systemen. Door te begrijpen hoe agents states waarnemen, actions kiezen, rewards ontvangen en policies bijwerken, wordt duidelijk hoe intelligent gedrag kan ontstaan uit eenvoudige interacties.
De veelzijdigheid van dit framework verklaart waarom reinforcement learning wordt toegepast in zo uiteenlopende domeinen—van robotica en games tot financiën en aanbevelingssystemen. Dezelfde basisstructuur past zich aan totaal verschillende omgevingen aan, terwijl de kernprincipes van leren behouden blijven.