De meeste AI die we tot nu toe hebben besproken leert van voorbeelden. Een computer vision-systeem bestudeert duizenden gelabelde foto’s om katten te herkennen. Een taalmodel leest enorme hoeveelheden tekst om het volgende woord te voorspellen. Maar er is ook een manier van leren die veel dichter ligt bij hoe mensen dingen ontdekken: trial-and-error.
Denk aan leren fietsen. Niemand geeft je een boek met duizenden voorbeelden van “goed” en “fout” fietsen. In plaats daarvan stap je op, probeert je te trappen, valt waarschijnlijk om, past je aanpak aan en wordt geleidelijk beter door oefening. Je leert van de gevolgen van je acties—rechtop blijven voelt goed, vallen doet pijn.
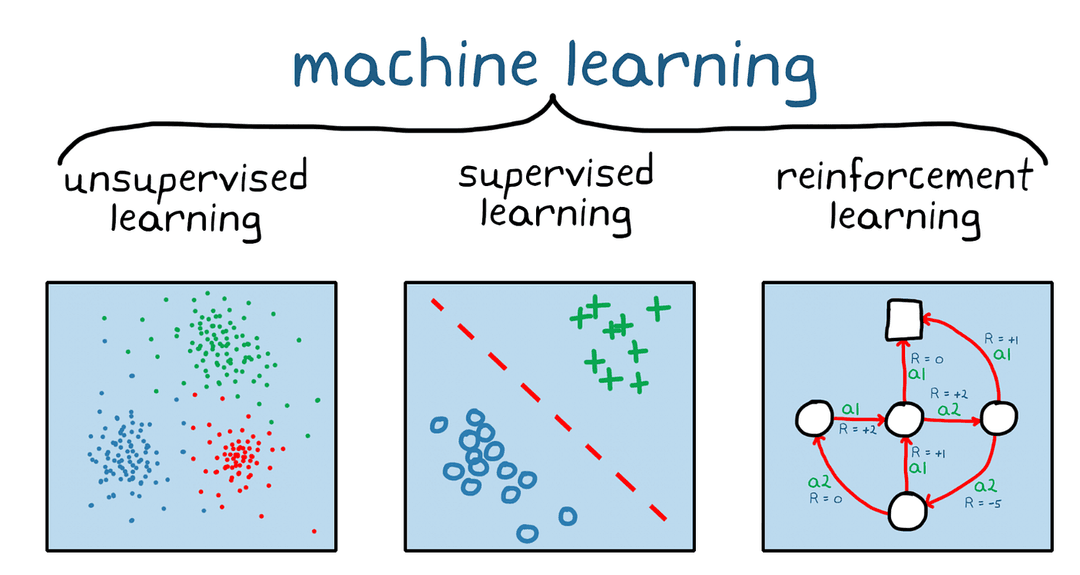
Precies zo werkt reinforcement learning. In plaats van leren uit vooraf gelabelde data, leren AI-systemen door acties te ondernemen in een omgeving, te zien wat er gebeurt en hun gedrag aan te passen op basis van beloning of straf.
Leren Zonder Leraar
Het belangrijkste verschil met andere leermethoden zit in de informatiestroom:
- Supervised learning: “Hier zijn 10.000 foto’s gelabeld als ‘kat’ of ‘hond’. Leer het verschil.”
- Unsupervised learning: “Hier is een stapel ongelabelde foto’s. Groepeer gelijke bij elkaar en ontdek patronen.”
- Reinforcement learning: “Hier is een spel. Probeer dingen, kijk wat er gebeurt en ontdek hoe je een hoge score haalt.”
Dit onderscheid is cruciaal omdat veel echte problemen geen nette labels of duidelijke juiste antwoorden hebben. Hoe navigeert een robot door een rommelige kamer? Hoe bied je de juiste producten aan klanten aan? Welke zetten leiden tot winst in schaken? Zulke vragen worden alleen beantwoord door ervaring.
RL-agents moeten effectieve strategieën zelf ontdekken. Ze krijgen geen directe instructie—alleen feedback over hoe goed ze bezig zijn.
De Leercyclus
Elke reinforcement learning-opzet volgt hetzelfde patroon:
- Observeer de huidige situatie.
- Kies een actie.
- Handel in de omgeving.
- Ontvang feedback.
- Leer van de ervaring.
- Herhaal de cyclus.
Dit creëert een continue feedbacklus waarin acties invloed hebben op nieuwe ervaringen, en die ervaringen toekomstige acties vormen.
🎮 Game-voorbeeld: Stel je een AI voor die Pac-Man leert spelen. In het begin beweegt het willekeurig. Bij het eten van een stip krijgt het punten (positieve feedback). Bij het raken van een spook verliest het een leven (negatieve feedback). Na duizenden potjes leert het dat stippen eten goed is, geesten vermijden cruciaal is, en power-ups een kans bieden om veilig geesten te achtervolgen.
Belangrijk is dat geen enkele programmeur heeft expliciet “vermijd geesten” gecodeerd heeft—het systeem ontdekte dit zelf.
Voorbeelden uit de Praktijk
Reinforcement learning weerspiegelt veel natuurlijke leervormen:
🚶🏻♂️ Een kind dat leert lopen: Probeert bewegingen, valt (negatieve feedback), zet stappen (positieve feedback) en verbetert door oefening.
🧑🏾🍳 Een chef die een recept perfectioneert: Past ingrediënten aan, proeft, let op reacties en verfijnt iteratief.
🚗 Een chauffeur in verkeer: Leert welke routes sneller zijn en hoe te reageren op omstandigheden door ervaring.
📈 Een bedrijf dat prijzen optimaliseert: Probeert verschillende prijzen, observeert verkoopresultaten en stelt strategieën bij.
In al deze gevallen ontstaat leren door actie, observatie van gevolgen en voortdurende verbetering.
Waarom Deze Aanpak Belangrijk Is
Reinforcement learning opent toepassingen die onmogelijk zijn met klassieke supervised learning:
- Dynamische omgevingen: De echte wereld verandert voortdurend; reinforcement learning kan zich aanpassen.
- Complexe beslissingsreeksen: Veel taken vereisen gecoördineerde acties, waarvan de waarde afhangt van latere stappen (zoals schaken).
- Personalisatie: Voorkeuren leren door interactie in plaats van expliciete labels.
- Optimalisatie: Strategieën ontdekken die prestaties (winst, efficiëntie, tevredenheid) maximaliseren.
Dit maakt reinforcement learning bijzonder geschikt voor onvoorspelbare omgevingen zonder constante menselijke begeleiding.
De Exploratie Uitdaging
Een fascinerend aspect van reinforcement learning is de balans tussen nieuwe dingen proberen (exploratie) en bestaande kennis benutten (exploitation).
🌆 Ontdekking Voorbeeld: In een nieuwe stad ben je op zoek naar lunch:
- Exploit: Naar McDonald’s gaan omdat je weet wat je krijgt.
- Explore: Een onbekend lokaal restaurant proberen.
Als je alleen maar exploiteert, loop je potentieel betere opties mis. Als je alleen maar onderzoekt, kun je eindigen met vreselijke maaltijden, terwijl je iets betrouwbaars had kunnen kiezen.
Reinforcement learning systemen worden voortdurend met dezelfde uitdaging geconfronteerd. Ze moeten nieuwe acties uitproberen om betere strategieën te ontdekken (verkenning) en tegelijkertijd hun huidige kennis gebruiken om goed te presteren (exploitatie). Verschillende situaties vragen om verschillende balansen: u kunt meer onderzoeken als de inzet laag is en meer exploiteren als de prestaties van cruciaal belang zijn.
Van Simpele Regels naar Complex Gedrag
Wat reinforcement learning bijzonder krachtig maakt, is dat eenvoudige leerregels kunnen leiden tot verfijnd gedrag. Systemen hoeven complexe strategieën niet vooraf te begrijpen—ze kunnen deze door ervaring zelf ontdekken.
Stel je voor hoe een reinforcement learning-systeem leert om een strategisch bordspel te spelen:
- In het begin: De zetten lijken willekeurig omdat het systeem alles probeert.
- Vroege fase van leren: Het herkent duidelijk slechte zetten (zoals onnodig stukken weggeven).
- Patroonherkenning: Het begint veelvoorkomende tactische patronen te zien en hier goed op te reageren.
- Strategisch denken: Uiteindelijk ontwikkelt het langetermijnplanning en geavanceerde strategieën.
Geen van deze vaardigheden werd direct geprogrammeerd. Ze ontstaan uit het eenvoudige proces van acties proberen, feedback ontvangen en de prestaties stap voor stap verbeteren.
Juist deze opkomende complexiteit maakt reinforcement learning zo spannend—en soms verrassend. Systemen ontdekken vaak strategieën waar menselijke experts nooit aan hadden gedacht, wat leidt tot doorbraken in spellen, optimalisatieproblemen en andere complexe domeinen.
De Basis voor Moderne AI
Veel van de meest indrukwekkende AI-mogelijkheden van vandaag zijn terug te voeren op principes uit reinforcement learning. De gespreksvaardigheden van ChatGPT zijn bijvoorbeeld verfijnd met reinforcement learning from human feedback—het systeem leerde reacties te genereren die door mensen als behulpzamer, onschadelijker en eerlijker werden beoordeeld.
Aanbevelingssystemen leren van interacties met gebruikers: welke items mensen aanklikken, kopen of positief beoordelen. Zelfrijdende auto’s leren van miljoenen kilometers rijervaring. Handelsalgoritmes passen zich aan veranderende marktomstandigheden aan door continu te interacteren met financiële data.
Inzicht in reinforcement learning helpt te verklaren hoe AI-systemen doelen, strategieën en zelfs voorkeuren lijken te ontwikkelen—niet omdat die vooraf zijn ingeprogrammeerd, maar omdat ze voortkomen uit het fundamentele proces van leren door ervaring en feedback.
Belangrijkste Inzichten
Reinforcement learning is een fundamenteel andere AI-aanpak die natuurlijke leerprocessen weerspiegelt. In plaats van gelabelde data te vereisen, leert RL door trial-and-error en geleidelijke verbetering.
Dit stelt AI in staat dynamische, complexe problemen aan te pakken zonder vooraf bekende oplossingen. Van game-kampioenen tot gepersonaliseerde aanbevelingen: RL voedt enkele van de krachtigste en meest bruikbare AI-toepassingen van vandaag.