Tot nu toe hebben we gezien hoe neurale netwerken kunnen herkennen wat er in een afbeelding staat—katten, auto’s, verkeersborden—en hoe ze visuele features extraheren om die oordelen te maken. Maar wat als we het probleem omdraaien? In plaats van identificeren wat er al is, kan een model iets nieuws creëren?
Dit is het domein van generatieve modellen: AI-systemen die beelden kunnen “bedenken” die nooit eerder hebben bestaan. Van het produceren van realistische menselijke gezichten tot het genereren van surrealistische kunstwerken uit tekstprompts—generatieve AI is in slechts een paar jaar geëvolueerd van onderzoeksnieuwigheid tot cultureel fenomeen.
Van Herkenning Naar Creatie
De sprong van herkenning naar generatie is minder mysterieus dan het klinkt.
- Bij classificatie leert een netwerk features die categorieën onderscheiden.
- Bij generatie gebruikt een netwerk die features omgekeerd: pixels samenstellen die lijken op de geleerde patronen.
De eerste hint kwam van autoencoders. Deze netwerken leren een afbeelding te comprimeren tot een compacte code (de latente representatie) en die vervolgens weer te reconstrueren.
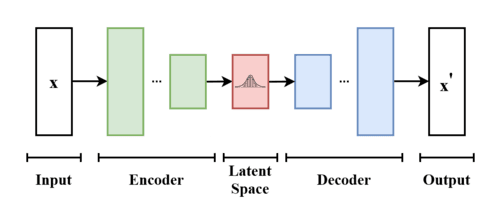
Als een autoencoder een afbeelding kan reconstrueren vanuit een code, waarom dan geen nieuwe codes invoeren en kijken wat er gebeurt? Het probleem: willekeurige codes produceren meestal ruisachtige vlekken. Om plausibele afbeeldingen te genereren, moeten modellen de verborgen regels van visueel realisme leren—texturen, proporties, belichting, perspectief.
Daar beginnen moderne generatieve modellen.
Variational Autoencoders: Leren Om Te Samplen
Variational Autoencoders (VAE’s) breiden het autoencoder-idee uit door latente codes probabilistisch te maken in plaats van vast. In plaats van een afbeelding naar één enkel punt te mappen, mapt de encoder deze naar een volledige kansverdeling—beschreven door een gemiddelde en variantie, net zoals toen we naar lengtes keken die een normale verdeling volgden in Hoofdstuk 2.
Training balanceert twee doelen:
- Reconstructieverlies: de originele afbeelding nauwkeurig herbouwen.
- Regularisatieverlies: latente codes vormen naar een normale verdeling (klokvorm).
Eenmaal getraind kun je:
- Getallen samplen uit deze verdeling.
- Ze door de decoder sturen.
- Helemaal nieuwe, maar realistisch ogende afbeeldingen krijgen.
De VAE-architectuur lijkt op die van de autoencoder, maar dit keer sampelen we met behulp van waarschijnlijkheden:

VAE’s zijn vooral goed in interpolatie: soepel mengen tussen concepten. Bijvoorbeeld, van een handgeschreven “3” naar een “5” schuiven levert geleidelijk veranderende cijfers op.
Generative Adversarial Networks: Het AI-Kunstduel
GAN’s (Generative Adversarial Networks) kiezen een gedurfder aanpak: ze trainen twee netwerken in competitie.
- Generator: probeert nepafbeeldingen te maken.
- Discriminator: probeert echt van nep te onderscheiden.
Training werkt als een wapenwedloop:
- Generator produceert afbeeldingen uit willekeurige ruis.
- Discriminator beoordeelt echt vs nep.
- Generator past zich aan om de discriminator beter te misleiden.
- Discriminator scherpt zijn detectie aan.
Na verloop van tijd leert de generator afbeeldingen te maken die zo realistisch zijn dat de discriminator het verschil niet meer ziet.
👮🏼 Criminele Vervalsing Voorbeeld: GAN’s werken als vervalsers en politie: de generator vervalst geld terwijl de discriminator het probeert te ontmaskeren. Naarmate beiden verbeteren, worden de vervalsingen zo overtuigend dat zelfs de “politie” ze niet meer kan onderscheiden.

GAN’s produceren doorgaans scherpere, gedetailleerdere beelden dan VAE’s, maar zijn berucht moeilijk te trainen.
Sampling In Generatieve Modellen
Zodra een generatief model is getraind, creëren we nieuwe afbeeldingen door sampling. Dit proces zet abstracte latente codes of willekeurige ruis om in zichtbare pixels.
Latente-Ruimte-Sampling: In modellen zoals VAE’s en GAN’s leven afbeeldingen in een gecomprimeerde wiskundige ruimte die de latente ruimte heet. Elk punt in deze ruimte komt overeen met een mogelijke afbeelding. Door punten uit deze ruimte te samplen en te decoderen, genereren we nieuwe afbeeldingen.
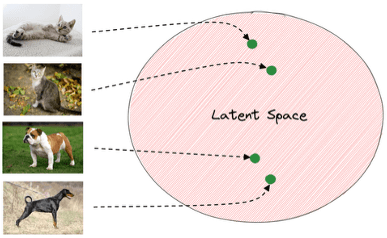
Interessant is dat nabijgelegen punten in de latente ruimte vergelijkbare afbeeldingen produceren. Soepel door de ruimte bewegen laat ons interpoleren tussen categorieën—bijvoorbeeld een handgeschreven ‘3’ morphen naar een ‘5’ of eigenschappen van katten en honden mengen.
Progressief Samplen: Diffusion-modellen kiezen een andere aanpak: in plaats van direct te samplen, beginnen ze met willekeurige ruis en verfijnen die stap voor stap totdat een samenhangend beeld ontstaat.

Dit progressieve denoising stelt moderne tekst-naar-beeldsystemen in staat om gedetailleerde, realistische afbeeldingen te creëren die door prompts worden gestuurd. Bij elke stap gebruikt het model waarschijnlijkheden—net zoals taalmodellen dat doen bij het kiezen van het volgende woord—om te bepalen hoe pixels worden aangepast totdat ruis structuur wordt.
Waarom Sampling Belangrijk Is
Sampling is niet zomaar een technisch detail—het is waar de creativiteit van het model plaatsvindt. Hetzelfde model kan eindeloos verschillende outputs genereren afhankelijk van waar je sampled, waardoor generatieve AI diversiteit, variatie en verrassing biedt.
Een Decennium Van Vooruitgang
De visuele kwaliteit van generatieve modellen is verbluffend snel verbeterd:
- Vroege jaren 2010: wazige vlekken, nauwelijks herkenbare cijfers of gezichten.
- 2014–2018 (GAN-tijdperk): scherpere texturen, gezichten en objecten op -resolutie.
- 2018–2020 (StyleGAN & anderen): hoge-resolutie portretten (), fotorealistische kwaliteit, gedetailleerde controle over attributen zoals “maak de persoon ouder” of “voeg een bril toe.”
- 2020s (Diffusion-modellen): tekst-naar-beeldgeneratie op professioneel niveau; veelzijdig genoeg voor zowel realisme als kunst.
Deze snelle progressie laat zien hoe generatieve modellen evolueerden van ruwe schetsen tot tools die in staat zijn beeldmateriaal te produceren op een niveau dat menselijke kunstenaars evenaart.
Tekst-Naar-Beeld: Woorden Omzetten In Afbeeldingen
Misschien wel de meest verbluffende sprong is tekst-naar-beeldgeneratie: typ een beschrijving, krijg een afbeelding.
- “Een olieverfschilderij van een vos in de stijl van Van Gogh”.
- “Een foto van een golden retriever met een zonnebril op een strand”.
Hoe het werkt in grote lijnen:
- Een taalencoder zet de prompt om in een semantische representatie.
- Een cross-modale brug koppelt tekstconcepten aan visuele concepten.
- Een generator (vaak een diffusion-model) produceert geleidelijk een afbeelding die overeenkomt met de beschrijving.
Deze systemen zijn getraind op miljoenen afbeelding-bijschriftparen en leren hoe taal correspondeert met visuele features. Net als een autoencoder die is opgesplitst in encoder en decoder, comprimeert de tekstencoder betekenis in een representatie, en decodeert de afbeeldingsgenerator die weer terug naar pixels.
Praktische Toepassingen
Generatieve modellen zijn niet alleen leuke speeltjes; ze hervormen creatieve en professionele workflows. Je hebt ze waarschijnlijk zelf al eens gebruikt om verschillende redenen. Maar denk eens aan de impact die deze modellen kunnen hebben:
🎨 Kunst & Design: Kunstenaars en ontwerpers gebruiken ze voor conceptkunst, illustraties, stijltransfer en snelle prototyping, waarmee ze werk dat uren kostte terugbrengen tot minuten.
🎬 Entertainment: In film, tv en gaming helpen ze bij het genereren van assets, visuele effecten en zelfs ideeën voor kostuums en sets, waardoor kosten dalen en creatieve mogelijkheden groeien.
🏭 Industrie: Bedrijven gebruiken generatieve modellen voor productmockups, architecturale visualisatie en marketingafbeeldingen, wat pipelines stroomlijnt en ontwikkelingscycli verkort.
🌍 Toegankelijkheid: Misschien wel het belangrijkste: ze stellen niet-kunstenaars en kleine teams in staat om visuals van professioneel niveau te maken, waardoor drempels worden verlaagd en creativiteit wordt gedemocratiseerd.
Gezamenlijk laten deze toepassingen zien hoe generatieve modellen niet alleen veranderen hoe we creëren, maar ook wie kan deelnemen aan het creatieve proces.
Belangrijkste Inzichten
Generatieve modellen markeren een keerpunt: van AI als hulpmiddel dat herkent naar AI als hulpmiddel dat creëert. VAE’s introduceerden gestructureerde latente ruimtes voor sampling, GAN’s verscherpten realisme via competitie, en diffusion-modellen maken nu krachtige tekst-naar-beeldgeneratie mogelijk.
Ze hebben kunst, design, media en onderzoek al getransformeerd—en ze bereiden het toneel voor AI-systemen die steeds creatiever met mensen kunnen samenwerken.