AI leert van data, maar ruwe data is vaak rommelig, verwarrend en vol verrassingen. Voordat AI slimme voorspellingen kan doen, moet het begrijpen wat de data ons eigenlijk vertelt. Dit is waar statistiek in beeld komt—het is als een gesprek met je data om de geheimen ervan te leren kennen.
Statistiek helpt AI cruciale vragen te beantwoorden zoals: Wat is typisch in deze dataset? Hoeveel variëren de waarden? Zijn er verborgen patronen of problematische biases? Zonder deze inzichten kan AI de verkeerde lessen leren en slechte beslissingen nemen.
Zie statistiek als het factcheckproces van AI, dat ervoor zorgt dat de data logisch is voordat die wordt gebruikt om belangrijke voorspellingen te doen.
Data Samenvatten: Gemiddelde, Mediaan en Variantie
Wanneer je veel data hebt, heb je manieren nodig om snel te begrijpen wat het je vertelt. Statistiek biedt verschillende hulpmiddelen om informatie samen te vatten en belangrijke patronen te ontdekken.
🍋 Limonadekraam Voorbeeld: Laten we teruggaan naar onze limonadekraam en de dagelijkse verkoop gedurende een week bijhouden. Dit is hoeveel bekers je elke dag verkocht:
Deze lijst met getallen vertelt ons niet meteen veel. Laten we statistische hulpmiddelen gebruiken om te begrijpen wat er echt gebeurt.
1. Gemiddelde
Het gemiddelde geeft ons de algemene trend door alle waarden op te tellen en te delen door het aantal:
Dus gemiddeld verkoop je ongeveer 19 bekers per dag.
2. Mediaan (Middelste Waarde)
De mediaan vindt de middelste waarde wanneer alle getallen op volgorde zijn gezet:
Merk op dat de mediaan (14) behoorlijk verschilt van het gemiddelde (18.6). Dit vertelt ons iets belangrijks—dat één uitzonderlijk hoge dag (50 bekers) het gemiddelde omhoog trekt, terwijl je op de meeste dagen dichter bij 14 bekers verkoopt.
3. Variantie & Standaarddeviatie
Deze meten hoeveel je verkoop van dag tot dag varieert. Lage variantie betekent consistente verkoop; hoge variantie betekent onvoorspelbare verkoop.
In ons geval is de variantie hoog door die dag met 50 bekers. Dit vertelt ons dat je verkoop inconsistent is—sommige dagen zijn typisch, andere uitzonderlijk.
AI-systemen gebruiken deze statistische maten om patronen te begrijpen en voorspellingen te doen. Als een AI alleen naar het gemiddelde keek, zou het voorspellen dat je altijd ongeveer 19 bekers verkoopt. Maar de mediaan en variantie onthullen dat de meeste dagen dichter bij 14 bekers liggen, met af en toe uitschieters.
Dataverdelingen
Data komt niet zomaar in willekeurige patronen—het volgt vaak voorspelbare vormen die verdelingen worden genoemd. Het begrijpen van deze vormen helpt AI te weten wat te verwachten en betere voorspellingen te maken.
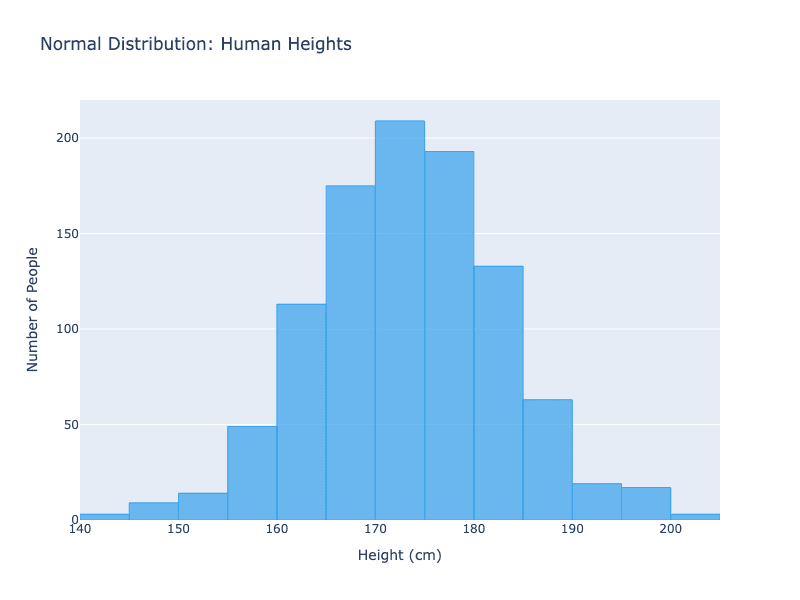
Normale Verdelen Voorbeeld: Lengtes van mensen volgen wat een "normale verdeling" of "klokvormige curve" wordt genoemd. De meeste mensen zitten rond de gemiddelde lengte, met minder mensen die erg klein of erg lang zijn. Dit creëert een symmetrisch, klokvormig patroon.
Scheve Verdelen Voorbeeld: Social media-engagement volgt een heel ander patroon. De meeste posts krijgen een paar likes of shares, maar een klein aantal gaat viraal met miljoenen interacties. Dit creëert een "scheve" verdeling—veel kleine waarden en een paar extreem grote.
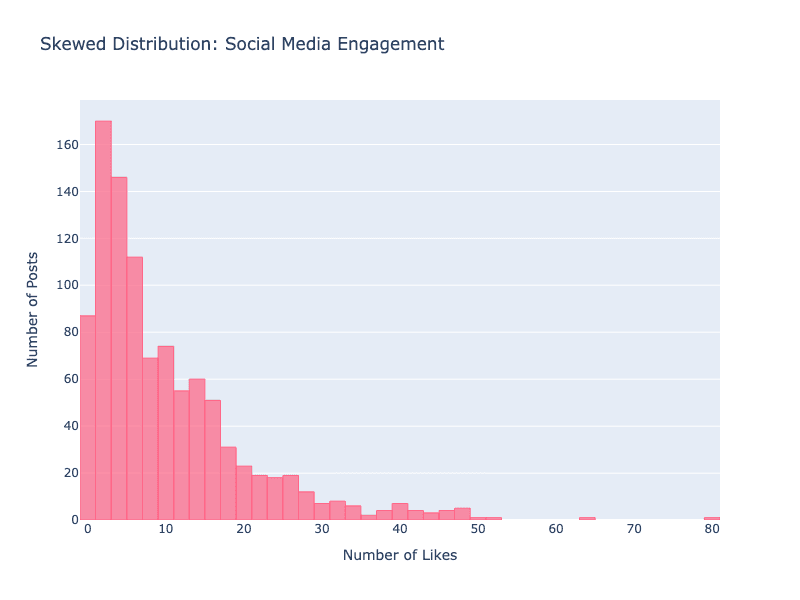
Als AI verwacht dat data één patroon volgt maar een ander tegenkomt, kan het slechte voorspellingen doen. Bijvoorbeeld, een AI die is getraind op normaal verdeelde data kan moeite hebben met sterk scheve social media-data en de kans op viraal content onderschatten.
Het begrijpen van de vorm van data helpt AI-systemen hun verwachtingen te kalibreren en nauwkeurigere voorspellingen te doen in verschillende scenario's.
Correlatie Versus Causaliteit: De Meest Voorkomende Fout Van AI
Een van de grootste valkuilen in AI is het verwarren van correlatie (dingen die samen gebeuren) met causaliteit (het ene veroorzaakt het andere echt). Deze fout kan leiden tot ernstig gebrekkige AI-systemen.
🦈 IJs En Haaienaanvallen Voorbeeld: Tijdens de zomermaanden nemen twee dingen toe:
- De verkoop van ijs stijgt.
- Het aantal haaienaanvallen neemt toe.
Een AI-systeem zou kunnen opmerken dat deze patronen samen optreden en concluderen dat ijsverkoop haaienaanvallen voorspelt. Maar dit zou volledig verkeerd zijn! De echte verklaring is dat warm weer beide fenomenen veroorzaakt—mensen kopen meer ijs als het warm is, en ze zwemmen vaker, waardoor ontmoetingen met haaien toenemen.
AI-systemen kunnen miljoenen correlaties in data vinden, maar de meeste vertegenwoordigen geen echte oorzaak-gevolgrelaties. Zonder zorgvuldige analyse kan AI aanbevelingen doen op basis van betekenisloze toevalligheden in plaats van echte inzichten.
Steekproeven En Bias: Wanneer AI De Verkeerde Lessen Leert
AI is slechts zo goed als de data waarvan het leert. Als die data bevooroordeeld, onvolledig of niet-representatief is, zal de AI een bevooroordeeld, onvolledig of onnauwkeurig begrip ontwikkelen.
🚗 Zelfrijdende Auto Voorbeeld: Stel je voor dat je een AI voor zelfrijdende auto's traint met alleen beeldmateriaal van zonnige snelwegen. Deze AI werkt misschien goed in vergelijkbare omstandigheden, maar faalt rampzalig bij:
- Besneeuwde wegen.
- Drukke stadsstraten.
- Nachtelijke rijomstandigheden.
De AI heeft niet "geleerd" om slecht te zijn in deze situaties—het is er simpelweg nooit mee geconfronteerd tijdens training, dus het heeft geen idee hoe ermee om te gaan.
👨🏼💼 Hiring AI Voorbeeld: Als een AI-recruitmentsysteem is getraind op historische wervingsdata van een bedrijf dat eerder vooral mannen aannam voor technische functies, kan de AI concluderen dat man zijn een belangrijke kwalificatie is voor technische banen. Dit zet vroegere bias voort in plaats van daadwerkelijke functie-relevante vaardigheden te identificeren.
Goede AI vereist diverse, representatieve data die het volledige scala aan situaties dekt waarmee de AI te maken krijgt. Dit betekent actief op zoek gaan naar gevarieerde voorbeelden en bewust zijn van wat mogelijk ontbreekt in de trainingsdata.
Statistiek In Actie: Echte AI-Toepassingen
Laten we bekijken hoe deze statistische concepten worden toegepast in AI-systemen die je dagelijks tegenkomt:
🍿 Aanbevelingssystemen: Netflix gebruikt statistiek om je kijkpatronen te begrijpen. Het berekent je gemiddelde voorkeur voor filmlengte, identificeert je favoriete genres en meet hoeveel je smaak in de loop van de tijd varieert. Het kijkt ook naar correlaties tussen jouw voorkeuren en die van vergelijkbare gebruikers.
📧 E-mail Spamdetectie: Spamfilters gebruiken statistische analyse om verdachte patronen te identificeren. Ze berekenen het gemiddelde aantal uitroeptekens in spamberichten, meten hoe vaak bepaalde woorden voorkomen en zoeken naar ongebruikelijke patronen in afzenderinformatie.
🌦️ Weervoorspelling: Weer-AI analyseert statistische patronen in historische weerdata, kijkt naar gemiddelden, variaties en correlaties tussen verschillende atmosferische omstandigheden om toekomstige weerpatronen te voorspellen.
Belangrijkste Inzichten
Statistiek biedt AI essentiële hulpmiddelen om data te begrijpen voordat voorspellingen worden gedaan. Door gemiddelden te berekenen, variabiliteit te meten en verdelingen te identificeren, kan AI patronen herkennen en veelvoorkomende valkuilen vermijden. Het begrijpen van het verschil tussen correlatie en causaliteit voorkomt dat AI valse conclusies trekt, terwijl zorgvuldige aandacht voor steekproeven en bias ervoor zorgt dat AI leert van representatieve, hoogwaardige data. Deze statistische fundamenten zijn cruciaal voor het bouwen van AI-systemen die betrouwbare, eerlijke en nauwkeurige beslissingen nemen in toepassingen uit de echte wereld.