AI learns from data, but raw data is often messy, confusing, and full of surprises. Before AI can make smart predictions, it needs to understand what the data is actually telling us. This is where statistics comes in—it's like having a conversation with your data to learn its secrets.
Statistics helps AI answer crucial questions like: What's typical in this dataset? How much do values vary? Are there hidden patterns or problematic biases? Without these insights, AI might learn the wrong lessons and make poor decisions.
Think of statistics as AI's fact-checking process, ensuring the data makes sense before using it to make important predictions.
Summarizing Data: Mean, Median, and Variance
When you have lots of data, you need ways to quickly understand what it's telling you. Statistics provides several tools to summarize information and spot important patterns.
🍋 Lemonade Stand Example: Let's return to our lemonade stand and track daily sales over a week. Here's how many cups you sold each day:
This list of numbers doesn't immediately tell us much. Let's use statistical tools to understand what's really happening.
1. Mean (Average)
The mean gives us the overall trend by adding all values and dividing by the count:
So on average, you're selling about 19 cups daily.
2. Median (Middle Value)
The median finds the middle value when all numbers are arranged in order:
Notice that the median (14) is quite different from the mean (18.6). This tells us something important—that one unusually high day (50 cups) is pulling the average up, but most days you're selling closer to 14 cups.
3. Variance & Standard Deviation
These measure how much your sales vary from day to day. Low variance means consistent sales; high variance means unpredictable sales.
In our case, the variance is high because of that 50-cup day. This tells us your sales are inconsistent—some days are typical, others are exceptional.
AI systems use these statistical measures to understand patterns and make predictions. If an AI only looked at the mean, it might predict you'll always sell about 19 cups. But the median and variance reveal that most days are closer to 14 cups, with occasional outliers.
Data Distributions
Data doesn't just come in random patterns—it often follows predictable shapes called distributions. Understanding these shapes helps AI know what to expect and make better predictions.
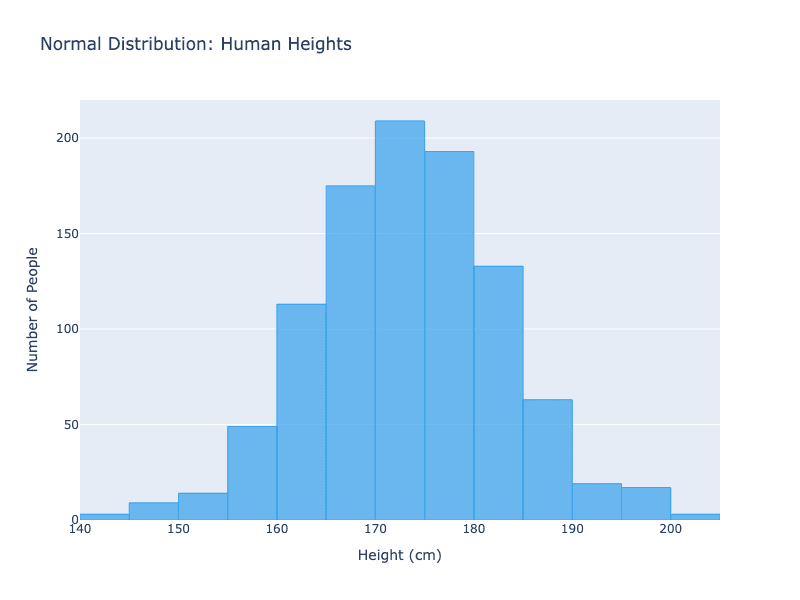
Normal Distribution Example: Human heights follow what is called a "normal distribution" or "bell curve". Most people cluster around the average height, with fewer people being very short or very tall. This creates a symmetric, bell-shaped pattern.
Skewed Distribution Example: Social media engagement follows a very different pattern. Most posts get a few likes or shares, but a tiny number go viral with millions of interactions. This creates a "skewed" distribution—lots of small values and a few extremely large ones.
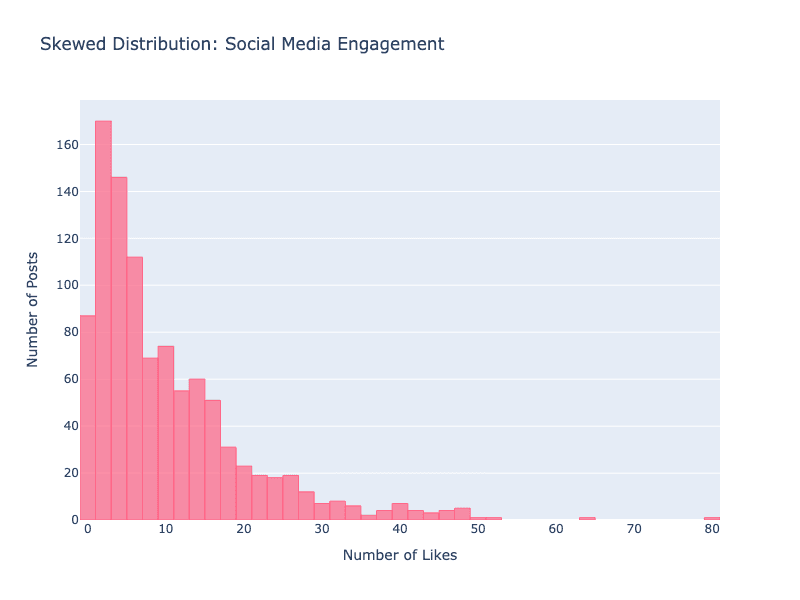
If AI expects data to follow one pattern but encounters another, it can make poor predictions. For example, an AI trained on normally distributed data might struggle with highly skewed social media data, underestimating the possibility of viral content.
Understanding the shape of data helps AI systems calibrate their expectations and make more accurate predictions across different scenarios.
Correlation vs. Causation: AI's Most Common Mistake
One of the biggest traps in AI is confusing correlation (things that happen together) with causation (one thing actually causing another). This mistake can lead to seriously flawed AI systems.
🦈 Ice Cream and Shark Attacks Example: During summer months, two things increase:
- Ice cream sales go up.
- Shark attacks increase.
An AI system might notice these patterns happen together and conclude that ice cream sales predict shark attacks. But this would be completely wrong! The real explanation is that hot weather causes both phenomena—people buy more ice cream when it's hot, and they swim more often, increasing encounters with sharks.
AI systems can find millions of correlations in data, but most don't represent real cause-and-effect relationships. Without careful analysis, AI might make recommendations based on meaningless coincidences rather than genuine insights.
Sampling and Bias: When AI Learns the Wrong Lessons
AI is only as good as the data it learns from. If that data is biased, incomplete, or unrepresentative, the AI will develop biased, incomplete, or inaccurate understanding.
🚗 Self-Driving Car Example: Imagine training a self-driving car AI using only footage from sunny highways. This AI might work well in similar conditions but fail catastrophically when encountering:
- Snow-covered roads.
- Busy city streets.
- Nighttime driving conditions.
The AI didn't learn to be "bad" at these situations—it simply never encountered them during training, so it has no idea how to handle them.
👨🏼💼 Hiring AI Example: If an AI recruitment system is trained on historical hiring data from a company that previously hired mostly men for engineering roles, the AI might conclude that being male is an important qualification for engineering jobs. This perpetuates past bias rather than identifying actual job-relevant skills.
Good AI requires diverse, representative data that covers the full range of situations the AI will encounter. This means actively seeking out varied examples and being aware of what might be missing from training data.
Statistics in Action: Real AI Applications
Let's see how these statistical concepts apply to AI systems you encounter every day:
🍿 Recommendation Systems: Netflix uses statistics to understand your viewing patterns. It calculates your average movie length preference, identifies your preferred genres, and measures how much your tastes vary over time. It also looks at correlations between your preferences and those of similar users.
📧 Email Spam Detection: Spam filters use statistical analysis to identify suspicious patterns. They calculate the average number of exclamation points in spam emails, measure how often certain words appear, and look for unusual patterns in sender information.
🌦️ Weather Prediction: Weather AI analyzes statistical patterns in historical weather data, looking at averages, variations, and correlations between different atmospheric conditions to predict future weather patterns.
Final Takeaways
Statistics provides AI with essential tools for understanding data before making predictions. By calculating averages, measuring variability, and identifying distributions, AI can spot patterns and avoid common pitfalls. Understanding the difference between correlation and causation prevents AI from drawing false conclusions, while careful attention to sampling and bias ensures AI learns from representative, high-quality data. These statistical foundations are crucial for building AI systems that make reliable, fair, and accurate decisions in real-world applications.