So far we’ve seen how neural networks can recognize what’s in an image—cats, cars, road signs—and how they extract visual features to make those judgments. But what if we flip the problem? Instead of identifying what’s already there, can a model create something new?
This is the realm of generative models: AI systems that can “dream up” images that never existed before. From producing realistic human faces to generating surreal artwork from text prompts, generative AI has gone from research curiosity to cultural phenomenon in just a few years.
From Recognition to Creation
The leap from recognition to generation is less mysterious than it sounds.
- In classification, a network learns features that separate categories.
- In generation, a network uses those features in reverse: assembling pixels that look like the learned patterns.
The first hint came from autoencoders. These networks learn to compress an image into a compact code (the latent representation) and then reconstruct it.
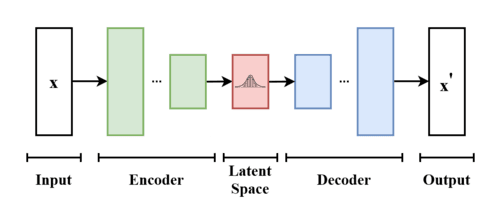
If an autoencoder can reconstruct an image from a code, why not feed in new codes and see what happens? The problem: random codes usually produce noisy blobs. To generate plausible images, models need to learn the hidden rules of visual realism—textures, proportions, lighting, perspective.
That’s where modern generative models begin.
Variational Autoencoders: Learning to Sample
Variational Autoencoders (VAEs) extend the autoencoder idea by making latent codes probabilistic rather than fixed. Instead of mapping an image to a single point, the encoder maps it to a full probability distribution—described by a mean and variance, just like when we looked at heights following a normal distribtion in Chapter 2.
Training balances two goals:
- Reconstruction loss: accurately rebuild the original image.
- Regularization loss: shape latent codes to follow a normal distribution (bell curve).
Once trained, you can:
- Sample numbers from this distribution.
- Pass them through the decoder.
- Get entirely new, but realistic-looking images.
The VAE architecture looks similar to the autoencoder architecture, but this time we sample using probabilities:

VAEs are especially good at interpolation: blending smoothly between concepts. For example, sliding from a handwritten “3” to a “5” produces gradually morphing digits.
Generative Adversarial Networks: The AI Art Duel
GANs (Generative Adversarial Networks) take a bolder approach: they train two networks in competition.
- Generator: tries to create fake images.
- Discriminator: tries to tell real from fake.
Training works like an arms race:
- Generator produces images from random noise.
- Discriminator judges real vs fake.
- Generator updates to fool the discriminator better.
- Discriminator sharpens its detection.
Over time, the generator learns to produce images so realistic that the discriminator can no longer tell the difference.
👮🏼 Catching Criminals Example: GANs work like counterfeiters and police: the generator forges fake money while the discriminator tries to spot it. As each improves, the fakes become so convincing that even the “police” can’t tell them apart.

GANs tend to produce sharper, more detailed images than VAEs, but they’re notoriously unstable to train.
Sampling in Generative Models
Once a generative model has been trained, the way we actually create new images is through sampling. This process turns abstract latent codes or random noise into visible pixels.
Latent Space Sampling: In models like VAEs and GANs, images live in a compressed mathematical space called the latent space. Each point in this space corresponds to a possible image. By sampling points from this space and decoding them, we generate new images.
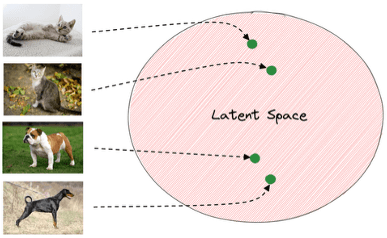
Interestingly, nearby points in latent space tend to produce similar images. Moving smoothly across the space lets us interpolate between categories—for example, morphing a handwritten ‘3’ into a ‘5’ or blending features of cats and dogs.
Progressive Sampling: Diffusion models take a different approach: instead of sampling directly, they start with random noise and gradually refine it step by step until a coherent image emerges.

This progressive denoising is what allows modern text-to-image systems to create detailed, realistic images guided by prompts. At each step, the model uses probabilities—just as language models do when picking the next word—to decide how to adjust pixels until noise becomes structure.
Why Sampling Matters
Sampling isn’t just a technical detail—it’s where the creativity of the model happens. The same model can generate endlessly different outputs depending on where you sample, giving us diversity, variation, and surprise in generative AI.
A Decade of Progress
The visual quality of generative models has improved astonishingly fast:
- Early 2010s: blurry blobs, barely recognizable digits or faces.
- 2014–2018 (GAN era): sharper textures, faces and objects at resolution.
- 2018–2020 (StyleGAN & others): high-res portraits (), photorealistic quality, fine-grained control over attributes like “make the person older” or “add glasses.”
- 2020s (Diffusion models): text-to-image generation at professional quality; versatile enough for both realism and art.
This rapid progression shows how generative models evolved from crude sketches to tools capable of producing imagery at a level rivaling human artists.
Text-to-Image: Turning Words into Pictures
Perhaps the most dazzling leap is text-to-image generation: type a description, get a picture.
- “An oil painting of a fox in the style of Van Gogh”.
- “A photograph of a golden retriever wearing sunglasses on a beach”.
How it works in broad strokes:
- A language encoder converts the prompt into a semantic representation.
- A cross-modal bridge maps text concepts to visual concepts.
- A generator (often a diffusion model) gradually produces an image that matches the description.
These systems are trained on millions of image–caption pairs, learning how language maps onto visual features. Much like an autoencoder split into encoder and decoder, the text encoder compresses meaning into a representation, and the image generator decodes it back into pixels.
Real World Applications
Generative models aren’t just fun toys; they’re reshaping creative and professional workflows. You have problably used them yourself for various reasons. But think about the impact these models might have:
🎨 Art & design: Artists and designers use them for concept art, illustrations, style transfer, and rapid prototyping, accelerating what once took hours into minutes.
🎬 Entertainment: In film, TV, and gaming, they help generate assets, visual effects, and even ideas for costumes and sets, reducing costs while expanding creative possibilities.
🏭 Industry: Companies rely on generative models for product mockups, architectural visualization, and marketing imagery, streamlining pipelines and shortening development cycles.
🌍 Accessibility: Perhaps most importantly, they empower non-artists and small teams to create professional-grade visuals, lowering barriers to entry and democratizing creativity.
Taken together, these applications show how generative models are transforming not only how we create, but also who gets to participate in the creative process.
Final Takeaways
Generative models mark a turning point: from AI as a tool that recognizes to AI as a tool that creates. VAEs introduced structured latent spaces for sampling, GANs sharpened realism through competition, and diffusion models now enable powerful text-to-image generation.
They’ve already transformed art, design, media, and research—and they set the stage for AI systems that can collaborate with humans in ever more creative ways.