Alles wat we tot nu toe hebben behandeld—woorden omzetten in getallen, embeddings, context en voorspelling—mondt uit in large language models (LLMs). Dit zijn de motoren achter ChatGPT, Claude en andere conversatiesystemen die essays kunnen schrijven, vragen beantwoorden en verrassend natuurlijke dialogen voeren.
Het principe is niet veranderd: ze voorspellen nog steeds het volgende woord. Wat anders is, is de schaal. Met miljarden parameters, datasets op internetschaal en enorme rekenkracht levert hetzelfde basisrecept plotseling kwalitatief nieuwe capaciteiten. Opschalen maakt voorspellingen niet alleen beter—het ontsluit vaardigheden zoals redeneren, programmeren en creatief schrijven.
Woordvoorspelling in Actie
In de kern van elk large language model staat nog steeds dezelfde taak: het voorspellen van het volgende woord met behulp van waarschijnlijkheden. Gegeven een reeks als “The capital of France is ___” berekent het model welke woorden het meest waarschijnlijk volgen, en kiest het volgende woord op basis van die waarschijnlijkheden.

Dit eenvoudige mechanisme—waarschijnlijkheidsgebaseerde woordvoorspelling—hebben we eerder onderzocht. Wat large language models opmerkelijk maakt, is wat er gebeurt wanneer je dit mechanisme opschaalt met miljarden parameters en data op internetschaal.
Van Language Models Naar Large Language Models
De verschuiving van vroege modellen naar LLMs is een van de meest dramatische schaalexperimenten in de geschiedenis van AI. De fundamentele taak—het voorspellen van het volgende woord—blijft hetzelfde, maar drie dingen groeiden met ordes van grootte:
- Modelgrootte: van miljoenen naar honderden miljarden parameters.
- Trainingsdata: van samengestelde corpora naar enorme delen van het internet.
- Rekenkracht: trainingsruns die duizenden processors wekenlang vereisen.
Deze groei volgt wat onderzoekers de scaling hypothesis noemen: naarmate modellen groter worden, verbetert de performance betrouwbaar. Bij bepaalde drempels verschijnen volledig nieuwe capaciteiten—niet geprogrammeerd, maar voortgekomen uit schaal zelf.
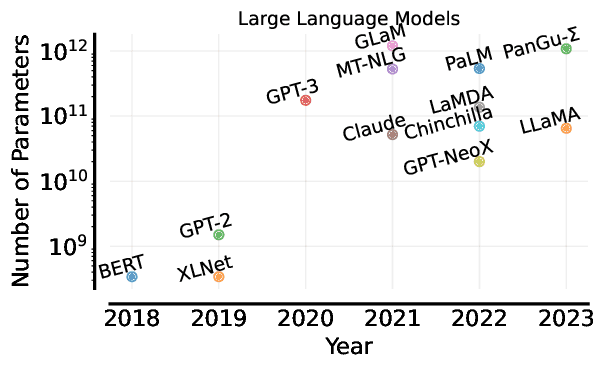
Training Op Internetschaal Data
Moderne LLMs trainen op datasets die proberen een groot deel van door mensen geschreven kennis vast te leggen. Boeken, nieuws, Wikipedia, wetenschappelijke artikelen, fora en miljarden webpagina’s dragen allemaal bij. GPT-3 alleen al werd getraind op ongeveer 500 miljard woorden—ongeveer een miljoen romans aan tekst.
Training op deze schaal brengt nieuwe uitdagingen met zich mee. Ruwe webdata is rommelig: het bevat spam, dubbele inhoud en schadelijk of laagwaardig materiaal. Onderzoekers moeten agressief filteren, terwijl ze toch genoeg diversiteit behouden om modellen breed inzetbaar te maken. De juiste balans vinden tussen kwantiteit en kwaliteit is een voortdurende puzzel.
Een ander opvallend kenmerk is diversiteit. Deze datasets beslaan tientallen talen en culturele contexten, wat cross-linguïstische vaardigheden en cultureel bewustzijn mogelijk maakt. Daarom kunnen LLMs vaak vertalen, slang herkennen of verwijzingen begrijpen die uit verschillende delen van de wereld komen.
Het Trainingsproces Op Schaal
Het trainingsproces is conceptueel eenvoudig, maar wordt op schaal een enorme technische onderneming. Het doel blijft het voorspellen van het volgende woord. Een model ziet een frase als “The capital of France is” en leert die voort te zetten met “Paris”. Maar het opschalen van dit doel vereist buitengewone middelen.
Trainingsruns worden verdeeld over duizenden processors, met miljarden parameters verspreid over veel machines. In de beginfase zijn voorspellingen grotendeels willekeurig. Met herhaalde passes door de data leert het model geleidelijk grammatica, daarna vocabulaire, daarna bredere feitelijke patronen. Na verloop van tijd beginnen capaciteiten zoals probleemoplossing en contextueel redeneren te ontstaan.
Deze schaal heeft een prijs. Het trainen van de grootste modellen kan miljoenen dollars aan rekenkracht vereisen en genoeg energie om duizenden huishoudens maandenlang van stroom te voorzien. Engineers monitoren zorgvuldig metrics zoals loss-reductie, gradientstabiliteit en opkomende capaciteiten om de training op koers te houden.
Opkomende Capaciteiten
Een van de meest fascinerende aspecten van LLMs is dat simpelweg groter maken vaardigheden oplevert die niet expliciet zijn geprogrammeerd. Een kleiner model kan alleen grammatica en veelvoorkomende woordassociaties nabootsen, maar op schaal beginnen nieuwe vaardigheden te verschijnen.
🤖 Few-Shot Learning Voorbeeld:
- Laat het model een paar Engelse–Franse vertalingen zien, en het kan het patroon voortzetten met nieuwe zinnen.
- Hetzelfde gebeurt met redeneertaken—na een paar voorbeelden kan het wiskundeproblemen oplossen of kleine stukjes code schrijven zonder extra training.
Daarbuiten integreren grote modellen kennis over vakgebieden heen. Ze kunnen vragen beantwoorden die geschiedenis met wetenschap combineren, of literatuur met filosofie. Ze wagen zich ook aan creativiteit: poëzie schrijven, grappen bedenken of verhalen genereren die genreconventies volgen. Misschien het meest indrukwekkend is dat ze uitgebreide dialogen kunnen volhouden en context over meerdere beurten kunnen volgen.
Van Basismodellen Naar Conversatie-AI
De ruwe modellen die uit training komen zijn krachtig, maar gedragen zich nog niet als behulpzame assistenten. Standaard gaan ze gewoon door met tekst, wat niet altijd nuttig is. Om ze om te vormen tot conversatiesystemen doorlopen ze extra trainingsstappen.
- Instruction tuning leert ze expliciete commando’s volgen in plaats van af te dwalen in vrije associatie.
- Alignment training moedigt ze aan behulpzaam, onschadelijk en eerlijk te zijn, als tegenwicht tegen bias en schadelijke inhoud in internetdata.
- Conversational fine-tuning stelt ze bloot aan dialoogdatasets, zodat ze leren hoe ze meerbeurtdialogen kunnen voeren en verduidelijkende vragen stellen.
- Menselijke feedback speelt een centrale rol: trainers rangschikken antwoorden en sturen modellen naar output die mensen het meest behulpzaam vinden.
Sommige organisaties fine-tunen deze modellen ook voor specifieke taken zoals onderwijs, klantenservice of creatief schrijven, waardoor ze voor bepaalde domeinen geschikt worden gemaakt.
De Architectuur Achter Moderne LLMs
De meeste moderne LLMs gebruiken de Transformer-architectuur uit Hoofdstuk 4, aangedreven door de attention-mechanismen die we eerder tegenkwamen. Op schaal wordt deze architectuur bijzonder krachtig.
Attention stelt het model in staat te beslissen welke delen van de context het belangrijkst zijn, en in grote modellen gebeurt dit over zeer lange sequenties—soms duizenden woorden. Multi-head attention betekent dat verschillende “heads” tegelijkertijd op verschillende dingen focussen: grammatica in het ene geval, semantische verbanden in een ander, langeafstandsverwijzingen in weer een ander.
Ook de diepte van deze netwerken is belangrijk. Tientallen of zelfs honderden gestapelde lagen bouwen geleidelijk abstractere representaties. Vroege lagen vatten grammatica; latere coderen wereldkennis en redeneerpatronen. Samen maken miljarden parameters verdeeld over deze componenten de capaciteiten mogelijk die we in de praktijk zien.
Capaciteiten En Beperkingen
LLMs kunnen samenhangend schrijven over vrijwel elk onderwerp, feitelijke vragen beantwoorden, talen vertalen, code genereren en gesprekken voeren die natuurlijk aanvoelen. Ze voeren deze taken vaak uit op of boven gemiddeld menselijk niveau.
Maar beperkingen blijven duidelijk. In de kern zijn LLMs voorspellingsmachines, geen redeneersystemen. Soms produceren ze vloeiende maar onjuiste antwoorden—de zogenaamde hallucinations. Hun kennis is bevroren op het moment van training, waardoor ze blind zijn voor recente gebeurtenissen. Ze kunnen ook inconsistent zijn: stel dezelfde vraag op twee manieren en je kunt twee verschillende antwoorden krijgen. En omdat ze enorme rekenkracht vereisen, is toegang tot de grootste modellen geconcentreerd bij een handvol goed gefinancierde organisaties.
De Sociale En Economische Impact
Deze systemen veranderen al hoe mensen werken, leren en creëren. Schrijvers, programmeurs en onderzoekers gebruiken ze als productiviteitstools voor het opstellen, coderen en samenvatten. Onderwijzers verkennen ze als tutors en assistenten, terwijl ze ook worstelen met hoe ze beoordeling en academische integriteit veranderen. Creatieve sectoren ervaren zowel kansen als verstoringen wanneer modellen verhalen, marketingteksten of ontwerpideeën genereren.
De economische implicaties zijn aanzienlijk. Taken die ooit veilig leken voor automatisering—documenten samenvatten, rapporten analyseren, klantvragen beantwoorden—worden steeds vaker door AI afgehandeld. Tegelijk roept de verspreiding van LLMs regelgevende en ethische vragen op: hoe bias te voorkomen, veiligheid te waarborgen en systemen met zo’n brede reikwijdte te reguleren.
👩🏻🏫 Bias Voorbeeld: Weet je nog dat we het hadden over bias in de bias–variance tradeoff? Daar betekende bias de neiging van een model om systematische fouten te maken omdat het te simpel is.
Maar als we over bias in large language models spreken, bedoelen we meestal sociale of culturele bias. Bijvoorbeeld: een LLM die is getraind op internetdata kan bepaalde beroepen sterker met één gender associëren—zoals “he is a doctor” en “she is a nurse” genereren—zelfs bij neutrale prompts.
De Toekomst van Large Language Models
De snelle vooruitgang van LLMs vertoont geen tekenen van vertraging. Onderzoekers verkennen verschillende richtingen:
- Verder opschalen: parameters en data nog verder oprekken, met nieuwe opkomende capaciteiten.
- Multimodale modellen: tekst combineren met beelden, audio en video voor rijker begrip.
- Efficiëntie: kleinere, goedkopere modellen bouwen die kunnen wedijveren met de giganten.
- Specialisatie: fine-tuning voor domeinen zoals geneeskunde, recht of wetenschappelijk onderzoek.
- Veiligheid en alignment: ervoor zorgen dat krachtige systemen betrouwbaar en nuttig blijven.
Samen wijzen deze richtingen naar een toekomst waarin large language models capabeler, toegankelijker en meer afgestemd op menselijke behoeften worden.
Belangrijkste Inzichten
Large language models zijn het resultaat van eenvoudige principes—het voorspellen van het volgende woord—toegepast op enorme schaal. Het resultaat is een systeem met opkomende capaciteiten in redeneren, creativiteit en conversatie. Maar dezelfde systemen blijven beperkt door voorspelling, bevroren kennis en inconsistentie.
Hun opkomst verandert nu al industrieën, onderwijs en samenleving. Zowel hun sterke punten als hun beperkingen begrijpen is essentieel terwijl we een toekomst navigeren waarin samenwerking tussen mens en AI deel wordt van het dagelijks leven.