Hoewel AI-systemen inherent complex zijn, hebben onderzoekers tal van technieken ontwikkeld om inzicht te krijgen in hoe ze informatie verwerken en beslissingen nemen. Deze variëren van eenvoudige visualisaties tot geavanceerde wiskundige analyses van neurale netwerken.
Het doel is niet volledige transparantie—vaak onmogelijk bij grote modellen—maar bruikbare inzichten die helpen bij toepassing, foutopsporing en verbetering. Verschillende technieken passen bij verschillende modellen en toepassingen, waardoor er een veelzijdige toolkit voor interpretatie is ontstaan.
Een belangrijke uitdaging is dat deze methoden systemen verklaren die niet redeneren zoals mensen. Hun output is een benadering—een vertaling van complexe wiskunde naar vormen die mensen kunnen begrijpen en gebruiken.
Feature Importance en Attribution Methoden
Een van de meest intuïtieve benaderingen is het identificeren van welke inputfeatures de grootste invloed hebben op modelvoorspellingen. Deze methoden beantwoorden de vraag: "Welke aspecten van de input waren het belangrijkst voor deze beslissing?".
- Globale feature importance: Laat zien welke features het vaakst invloedrijk zijn over veel voorspellingen heen. Een medisch model kan bijvoorbeeld steeds terugvallen op bepaalde symptomen of testresultaten.
- Lokale feature importance: Verklaart welke features belangrijk waren voor een specifieke voorspelling, en laat zien hoe een model bij verschillende patiënten andere factoren kan wegen.
- Gradient-based attribution: In neurale netwerken tonen gradients hoe gevoelig outputs zijn voor kleine veranderingen in de input, wat lokale feature importance oplevert.
Formeel kan feature importance zo gedefinieerd worden:
Met andere woorden: de belangrijkheid van feature kan worden gemeten door te kijken hoeveel de voorspelling verandert als dat feature wordt weggelaten.
🐘 Olifant-voorbeeld met afgeleiden: Bekijk hoe afgeleiden onthullen welke kenmerken van een olifant worden gebruikt om hem van de achtergrond te onderscheiden:

Deze methoden leveren intuïtieve verklaringen, maar kunnen misleidend zijn wanneer features op complexe manieren interacteren of wanneer modellen patronen gebruiken die mensen niet verwachten.
Attention-Visualisatie en Saliency Maps
Voor modellen die sequentiële of ruimtelijke data verwerken, laten attention- en saliency-methoden zien welke delen van de input de voorspellingen beïnvloeden.
Attention-mechanismen: In taalmodellen tonen attention-gewichten op welke woorden het systeem zich richt bij het genereren van tekst, wat linguïstische afhankelijkheden zichtbaar maakt.
Saliency maps: Bij afbeeldingen geven gradiënten aan welke pixels of regio’s de grootste invloed hebben op de classificatieresultaten:
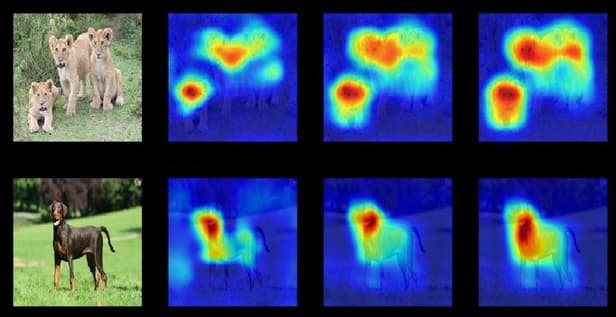
Deze methoden benadrukken vaak correlaties, maar hoge attention- of saliency-scores betekenen niet altijd dat er sprake is van echte causale belangrijkheid.
Voorbeelden van Feature Attribution-methoden
LIME (Local Interpretable Model-Agnostic Explanations)
LIME verklaart individuele voorspellingen door een complex model lokaal te benaderen met een eenvoudiger model (zoals lineaire regressie) rond een specifieke input. Voor tekst kan LIME benadrukken welke woorden de sentimentvoorspelling het meest beïnvloedden, en voor afbeeldingen toont het welke regio’s het meest bijdroegen aan de classificatie.
- Voordelen: Werkt met elk model, intuïtief, gericht op individuele voorspellingen.
- Beperkingen: Alleen lokaal bruikbaar, kan instabiel zijn, vereist veel modelruns.
SHAP (SHapley Additive exPlanations)
SHAP gebruikt ideeën uit de speltheorie om elke feature een “eerlijke bijdrage” toe te kennen aan een voorspelling. Het biedt zowel lokale verklaringen (per voorspelling) als globale inzichten (feature-importance over de hele dataset).
- Voordelen: Sterke theoretische basis, consistent, breed toegepast.
- Beperkingen: Kan computationeel zwaar zijn, en resultaten sluiten niet altijd aan bij menselijke intuïtie.
Samen vormen methoden zoals LIME en SHAP een kerninstrumentarium om complexe AI-systemen transparanter en betrouwbaarder te maken.
Probing en Activatieanalyse
Deze methoden onderzoeken welke concepten neurale netwerken leren door interne representaties te analyseren.
- Activatievisualisatie: Toont waar verschillende lagen gevoelig voor zijn—bijvoorbeeld vroege lagen die randen detecteren en latere die objecten herkennen.
- Probing classifiers: Eenvoudige classifiers testen of concepten zoals grammatica of semantiek aanwezig zijn in de verborgen representaties van een taalmodel.
Probing traint kleine modellen op de verborgen lagen van een groter netwerk om te zien of bepaalde concepten daaruit te halen zijn:
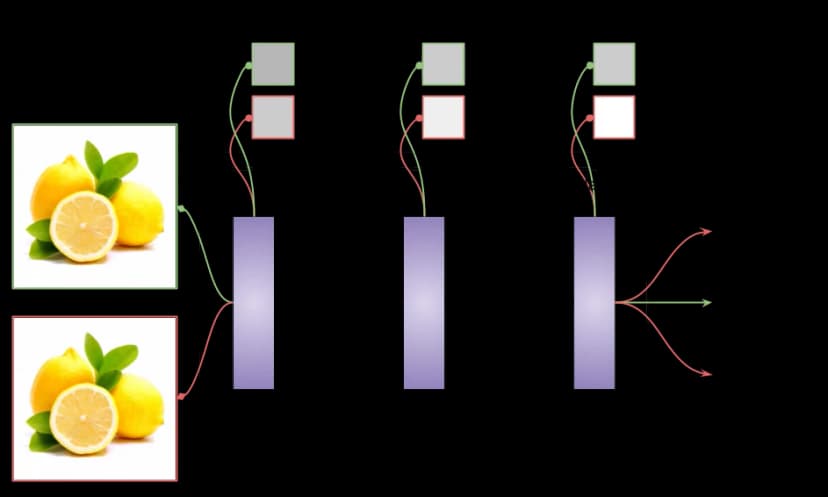
Probing toont correlaties, maar bewijst niet dat het model die concepten daadwerkelijk gebruikt in zijn besluitvorming.
Beperkingen en Uitdagingen van Huidige Methoden
Ondanks vooruitgang kampen Interpretatiemethoden met belangrijke uitdagingen die hun betrouwbaarheid en bruikbaarheid beperken.
- Faithfulness: Verklaringen kunnen aannemelijk klinken maar de werkelijke redenering van het model niet weerspiegelen.
- Stabiliteit: Kleine veranderingen in input kunnen tot heel andere verklaringen leiden.
- Menselijke biases: Mensen kunnen verklaringen die intuïtief aanvoelen te veel vertrouwen of verkeerd interpreteren.
- Model-specificiteit: Geen enkele aanpak werkt goed voor alle AI-systemen.
- Correlatie vs. causaliteit: De meeste methoden onthullen patronen, maar geen echte oorzakelijke drijfveren.
Deze beperkingen tonen aan dat interpretatie zowel zorgvuldig gebruik als blijvend onderzoek vereist.
Belangrijkste Inzichten
Interpretatiemethoden bieden waardevolle inzichten in AI-gedrag, maar zijn geen oplossing voor het black box-probleem. Elke methode heeft sterke punten, maar ook beperkingen en blinde vlekken.
Het vakgebied ontwikkelt zich snel, met voortdurend nieuwe technieken en verfijningen. In de praktijk geeft een combinatie van meerdere methoden, domeinkennis en zorgvuldige validatie het meest betrouwbare begrip. Het doel is niet volledige transparantie, maar voldoende inzicht om veilige toepassing, effectief debuggen en gepast vertrouwen in AI-systemen mogelijk te maken.