While AI systems are inherently complex, researchers have created many techniques to shed light on how they process information and make decisions. These range from simple visualizations to advanced mathematical analyses of neural network behavior.
The goal isn’t full understanding—often impossible for large models—but practical insights that guide deployment, debugging, and improvement. Different techniques suit different models and applications, forming a diverse interpretability toolkit.
A key challenge is that these methods explain systems that don’t reason like humans. Their outputs are approximations—translations of complex mathematics into forms people can interpret and use.
Feature Importance and Attribution Methods
One of the most intuitive interpretability approaches is identifying which input features most influence model predictions. These methods answer the question: "What aspects of the input mattered most for this decision?".
- Global feature importance: Highlights features most influential across many predictions. For example, a medical model might consistently rely on certain symptoms or test results.
- Local feature importance: Explains which features mattered for a specific prediction, showing how the same model may weigh symptoms differently for different patients.
- Gradient-based attribution: In neural networks, gradients show how sensitive outputs are to small input changes, providing local feature importance.
Feature importance can be defined as the change in model output when a feature is removed or altered:
So basically, this says the importance of feature can be found by testing the outcome of the model with and without that feature, and measuring how much the prediction changes.
🐘 Elephant Gradient Example: Take a look at how we can use the gradients to check what features of the elephant are used to separate it from the background:

These methods provide intuitive explanations but can be misleading when features interact in complex ways or when models use features differently than humans expect.
Attention Visualization and Saliency Maps
For models that process sequential or spatial data, attention and saliency methods reveal which parts of the input influence predictions.
Attention mechanisms: In language models, attention weights show which words the system focuses on when generating text, highlighting linguistic dependencies.
Saliency maps: For images, gradients indicate which pixels or regions most affect classification outcomes:
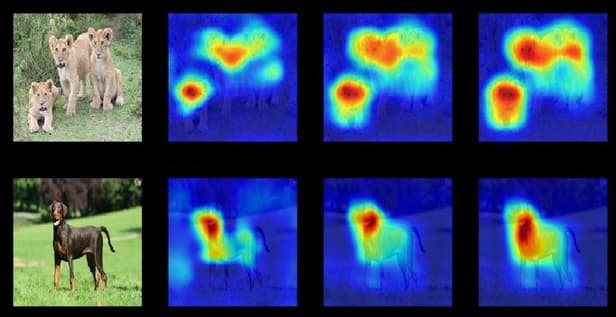
These methods have some important limitations. They might highlight correlations, but high attention or saliency doesn’t always mean true causal importance.
Examples of Feature Attribution Methods
LIME (Local Interpretable Model-Agnostic Explanations)
LIME explains individual predictions by approximating a complex model with a simpler one (like linear regression) around a specific input. For text, it can highlight which words most influenced a sentiment prediction; for images, it shows which regions contributed most to classification.
- Advantages: Works with any model, intuitive, focuses on single predictions.
- Limitations: Only local, can be unstable, requires many model runs.
SHAP (SHapley Additive exPlanations)
SHAP uses ideas from game theory to assign each feature a “fair share” of a prediction. It provides both local explanations (for single predictions) and global insights (feature importance across data).
- Advantages: Strong theoretical foundation, consistent, widely used.
- Limitations: Can be computationally heavy, and results may not align with human intuition.
Together, methods like LIME and SHAP form a core toolkit for making complex AI systems more transparent and trustworthy.
Probing and Activation Analysis
These methods explore what concepts neural networks learn by examining their internal representations.
- Activation visualization: Shows which features different layers respond to—for example, a vision model’s early layers detecting edges and later layers recognizing objects.
- Probing classifiers: Simple classifiers can test whether concepts like grammar or semantics are encoded in a language model’s hidden states.
Probing trains small models on the hidden layers of a larger network to test whether specific features or concepts can be extracted from its internal representations:
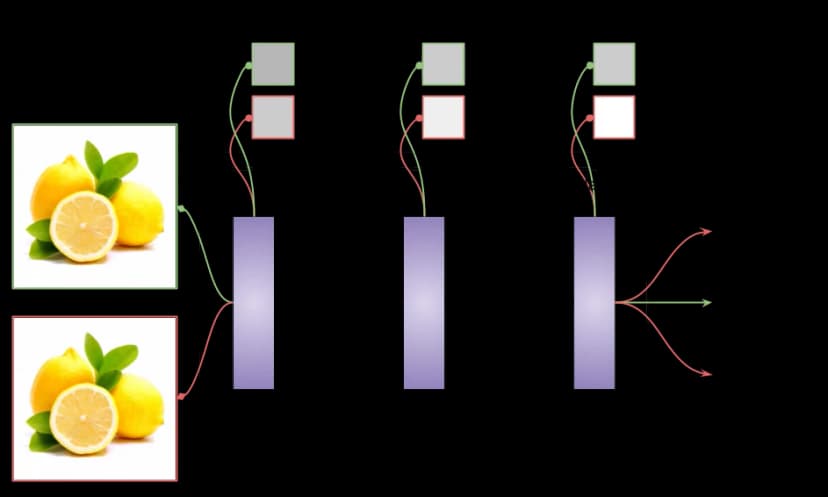
Probing reveals correlations but doesn’t prove the model actually uses those concepts in decision-making.
Limitations and Challenges of Current Methods
Despite progress, interpretability methods face key challenges that limit their reliability and usefulness.
- Faithfulness: Explanations may sound plausible but fail to reflect the model’s true reasoning.
- Stability: Small input changes can lead to very different explanations.
- Human biases: People may over-trust or misinterpret explanations that feel intuitive.
- Model specificity: No single approach works well across all AI systems.
- Correlation vs. causation: Most methods reveal patterns, not true causal drivers.
These limitations show why interpretability requires both careful use and continued research.
Final Takeaways
Interpretability methods offer useful insights into AI behavior, but they’re not a cure for the black box problem. Each method brings strengths alongside limitations and blind spots.
The field is evolving quickly, with new techniques and refinements emerging. In practice, combining multiple methods with domain expertise and careful validation provides the most reliable understanding. The goal isn’t perfect transparency, but enough insight to enable safe deployment, effective debugging, and appropriate trust in AI systems.