Gedurende vrijwel de hele geschiedenis is menselijke communicatie multimodaal geweest—een combinatie van woorden, gebaren, beelden en geluiden. Vragen als “Wat is er mis met deze afbeelding?” of het neuriën van een melodie zijn natuurlijke manieren om verschillende informatietypen te mengen.
Traditionele AI-systemen waren gescheiden per modaliteit: tekstmodellen behandelden woorden, beeldmodellen beelden en audiomodellen geluiden. Multimodale AI doorbreekt deze scheidslijnen en maakt systemen mogelijk die begrijpen en genereren over media heen—foto’s analyseren, beelden uit tekst creëren, spraak transcriberen of zelfs via video converseren.
Het resultaat is AI die natuurlijker en veelzijdiger aanvoelt—die kan “zien”, “horen” en reageren met de juiste mix van taal, beelden en geluid.
Voorbij Alleen Tekst Interacties
Enkelvoudige AI-modellen, hoe krachtig ook, missen veel van hoe mensen communiceren en problemen oplossen. In de echte wereld vereisen taken vaak het verwerken van meerdere informatietypen tegelijk:
- Visueel probleemoplossen: Uitleggen hoe iets kapot gerepareerd kan worden, grafieken analyseren of scènes beschrijven vereist visueel begrip naast taal.
- Audiocommunicatie: Gesprekken met stem, muziekanalyse en geluidherkenning vergen verwerking van audiosignalen die tekstmodellen niet aankunnen.
- Rijke contentcreatie: Presentaties, socialmediaposts en lesmateriaal combineren vaak tekst, beeld, audio en video.
- Toegankelijkheid: Mensen met visuele of auditieve beperkingen profiteren van AI die modaliteiten kan omzetten—beelden beschrijven, audio transcriberen of tekst visueel representeren.
Multimodale AI pakt deze beperkingen aan door meerdere inputtypen te verwerken en passende output te genereren in diverse mediavormen.
Hoe Multimodale AI Verschillende Media Verwerkt
Moderne multimodale systemen gebruiken neurale architecturen die verschillende mediatypen verwerken in gedeelde representatieruimtes—een soort gemeenschappelijke “taal” waarin modaliteiten vertaald kunnen worden.
Zo worden verschillende media verwerkt:
- Beelden: Via convolutionele netwerken of vision transformers die kenmerken, objecten, scènes en ruimtelijke relaties herkennen.
- Audio: Geluidsgolven worden omgezet in spectrogrammen en geanalyseerd om spraak, muziek of omgevingsgeluiden te identificeren.
- Video: Combineert beeldverwerking per frame met temporele analyse om beweging en patronen te begrijpen.
- Tekst: NLP-technieken geïntegreerd met andere modaliteiten voor rijkere interpretatie.
De doorbraak zit in gedeelde embeddings—wiskundige representaties waarin gelijke concepten uit verschillende modaliteiten dicht bij elkaar liggen.
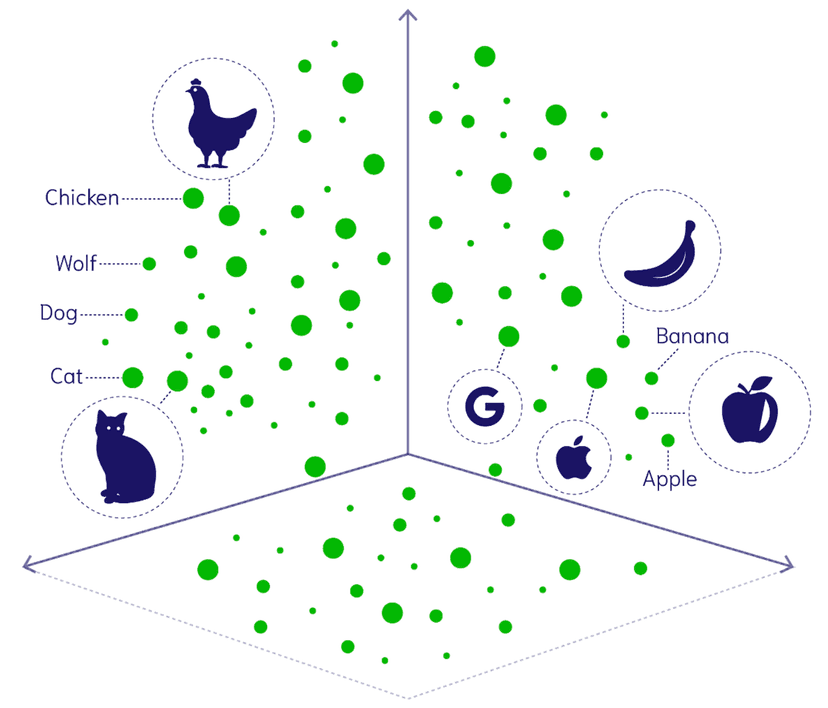
Visie-Taal Integratie
De combinatie van computer vision en NLP heeft indrukwekkende multimodale mogelijkheden gebracht:
- Beeldbeschrijving: Gedetailleerde tekstuele beschrijvingen van afbeeldingen genereren, inclusief objecten, relaties en context.
- Visuele vraagbeantwoording: Specifieke vragen beantwoorden over beeldinhoud—“Hoeveel mensen staan er op de foto?” of “Welke kleur heeft de auto?”
- Beeldgeneratie uit tekst: Systemen zoals DALL·E en Midjourney zetten beschrijvingen om in beelden.
- Documentbegrip: Rapporten en formulieren analyseren die tekst en beeld combineren, inclusief tabellen en diagrammen.
📊 Documentvoorbeeld: Je kunt een financieel rapport uploaden en vragen: “Wat waren de belangrijkste drijfveren van de omzetgroei?”. De AI analyseert zowel cijfers als grafieken voor een volledig antwoord.
Training van Multimodale Systemen
Multimodale AI vraagt om geavanceerde trainingsstrategieën:
- Data in paren: Datasets met dezelfde informatie in meerdere vormen (beelden met bijschriften, video’s met transcripties).
- Contrastief leren: Modellen trainen om te herkennen wanneer verschillende modaliteiten hetzelfde concept representeren.
- Cross-modale generatie: Systemen leren om modaliteiten te vertalen—tekst naar beeld, beeld naar audio, etc.
- Gezamenlijke representatie: Gedeelde wiskundige representaties ontwikkelen die betekenis vastleggen over modaliteiten heen.
Dit vergt enorme rekenkracht en zorgvuldig samengestelde data, maar levert AI op die flexibel omgaat met uiteenlopende informatietypen.
Toepassingen in de Praktijk
Multimodale AI transformeert talloze industrieën en gebruiksscenario's door meer natuurlijke en alomvattende interacties mogelijk te maken:
🎓 Onderwijs: Tutors die tekeningen analyseren, visuele concepten uitleggen en multimodale leermiddelen genereren.
🏥 Zorg: Medische AI die beelden analyseert, klachten uit spraak begrijpt en uitleg geeft in tekst en visuals.
🎨 Contentcreatie: AI die multimediapresentaties, marketingmateriaal en entertainment combineert uit tekst, beeld, audio en video.
Elke toepassing benut de menselijke neiging tot multimodale communicatie voor effectievere interactie.
Uitdagingen voor Multimodale AI
Ondanks indrukwekkende mogelijkheden worden multimodale AI-systemen geconfronteerd met een aantal belangrijke uitdagingen:
- Rekenintensiteit: Het parallel verwerken van meerdere modaliteiten vraagt veel rekenkracht.
- Data-alignment: Informatie uit verschillende modaliteiten moet correct worden gesynchroniseerd.
- Kwaliteitsconsistentie: Hoge kwaliteit behouden in alle modaliteiten is moeilijk.
- Contextbehoud: Betekenisvol blijven bij schakelen tussen of combineren van modaliteiten.
- Privacy: Gevoelige informatie zoals gezichten, stemmen en persoonlijke documenten vereist extra waarborgen.
Deze uitdagingen vragen zorgvuldig ontwerp en verder onderzoek.
De Toekomst van Multimodale Intelligentie
De ontwikkeling gaat richting naadlozere integratie:
- Realtime multimodale conversatie: Vloeiend schakelen tussen tekst, spraak, beeld en meer.
- Embodied AI: Robots die zien, horen, spreken en fysiek interacteren.
- Augmented reality integratie: Omgevingen begrijpen en verrijken met visuele en contextuele kennis.
- Gepersonaliseerde ervaringen: AI die communicatiestijl en modaliteit aanpast aan de gebruiker.
Deze vooruitgang wijst op AI die net zo natuurlijk en flexibel communiceert als mensen.
Belangrijkste Inzichten
Multimodale AI markeert de verschuiving van gespecialiseerde systemen naar AI die meerdere communicatiemodaliteiten beheerst. Door tekst, beeld, audio en video te combineren ontstaan interacties die natuurlijker, vollediger en toegankelijker zijn.
Begrip van multimodale capaciteiten verklaart waarom moderne AI-assistenten veelzijdiger aanvoelen: ze verwerken niet alleen tekst, maar ook de rijkdom van menselijke communicatie. Naarmate deze systemen verbeteren, zullen menselijke en AI-communicatiestijlen steeds meer in elkaar overlopen.