For most of history, human communication has been multimodal—we combine words, gestures, images, and sounds. Asking “What’s wrong with this picture?” or humming a tune are natural ways of mixing different types of information.
Traditional AI systems were siloed by modality: text models handled words, image models pictures, and audio models sounds. Multimodal AI removes these barriers, enabling systems that understand and generate across media—analyzing photos, creating images from text, transcribing speech, or even conversing through video.
The result is AI that feels more natural and versatile—able to “see,” “hear,” and respond with the right mix of language, visuals, and sound.
Beyond Text-Only Interactions
Single-modal AI systems, while powerful, miss much of how humans naturally communicate and solve problems. Real-world tasks often require processing multiple types of information simultaneously:
- Visual problem-solving: Explaining how to fix something broken, analyzing charts and graphs, or describing what's happening in a scene requires visual understanding alongside language.
- Audio communication: Voice conversations, music analysis, and sound identification involve processing audio signals that text-only systems cannot handle.
- Rich content creation: Modern communication often combines text, images, audio, and video in integrated presentations, social media posts, or educational materials.
- Accessibility needs: People with visual or hearing impairments benefit from AI that can convert between modalities—describing images, transcribing audio, or generating visual representations of text.
Multimodal AI addresses these limitations by processing multiple types of input and generating appropriate responses across different media formats.
How Multimodal AI Processes Different Media
Modern multimodal systems use sophisticated neural architectures to process different types of media through shared representational spaces—essentially creating a common "language" that different modalities can be translated into.
Here's how different media types are processed:
- Images: Visual content is processed through convolutional neural networks or vision transformers that identify features, objects, scenes, and spatial relationships.
- Audio: Sound waves are converted into spectrograms (visual representations of audio) and processed to identify speech, music, environmental sounds, or acoustic patterns.
- Video: Combines image processing for individual frames with temporal analysis to understand motion, sequences, and time-based patterns.
- Text: Natural language processing techniques we've already explored, but now integrated with other modalities for richer understanding.
The key breakthrough is learning shared embeddings—mathematical representations where similar concepts across different modalities end up close together in the same space:
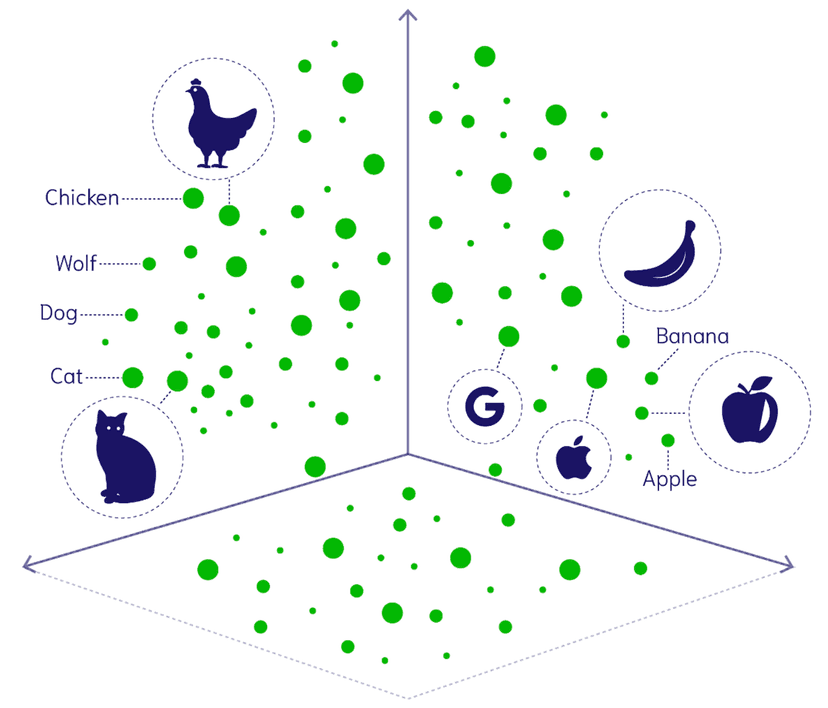
Vision-Language Integration
The combination of computer vision and natural language processing has created some of the most impressive multimodal capabilities:
- Image description: AI systems can generate detailed, natural language descriptions of images, identifying objects, relationships, activities, and even mood or context.
- Visual question answering: Instead of just describing images, these systems can answer specific questions about visual content—"How many people are in the photo?" or "What color is the car?"
- Image generation from text: Systems like DALL-E or Midjourney can create images from textual descriptions, translating linguistic concepts into visual representations.
- Document understanding: AI can process documents that combine text and visuals—analyzing charts, extracting information from forms, or understanding the layout and hierarchy of complex documents.
This integration enables more natural interactions where you can show rather than just tell, and receive visual as well as textual responses.
📊 Document Example: You can upload a complex financial report with charts and tables, then ask questions like "What were the main drivers of revenue growth?" and the AI can analyze both the numerical data and the visual presentations to provide comprehensive answers.
Training Multimodal Systems
Creating AI systems that work across multiple modalities requires sophisticated training approaches that go beyond single-modal datasets:
- Paired data training: Using datasets where the same information is available in multiple formats—images with captions, videos with transcripts, or audio with descriptions.
- Contrastive learning: Training systems to recognize when different modalities represent the same or related concepts, bringing similar concepts closer together in embedding space.
- Cross-modal generation: Teaching systems to translate between modalities—generating images from text, creating audio from visual cues, or producing text descriptions from multimedia content.
- Joint representation learning: Developing shared mathematical representations that capture meaning across different modalities in a unified framework.
These training approaches require enormous computational resources and carefully curated datasets, but they result in AI systems with human-like flexibility in handling different types of information.
Real-World Applications
Multimodal AI is transforming numerous industries and use cases by enabling more natural and comprehensive interactions:
🎓 Education: AI tutors that can analyze student drawings, explain visual concepts, generate educational content, and adapt to different learning modalities.
🏥 Healthcare: Medical AI that can analyze medical images, understand spoken symptoms, and generate comprehensive treatment explanations combining visual and textual information.
🎨 Content creation: AI systems that help create multimedia presentations, social media content, marketing materials, and entertainment by combining text, images, audio, and video.
Each application leverages the natural human tendency to communicate across multiple modalities for more effective and inclusive interactions.
Challenges in Multimodal AI
Despite impressive capabilities, multimodal AI systems face several significant challenges:
- Computational complexity: Processing multiple modalities simultaneously requires enormous computational resources, making these systems expensive to train and run.
- Data alignment: Ensuring that information across different modalities is properly synchronized and semantically aligned during training and inference.
- Quality consistency: Maintaining high quality across all modalities—a system might excel at text but struggle with image generation, creating uneven user experiences.
- Context preservation: Maintaining coherent context and meaning when switching between or combining different modalities within a conversation.
- Privacy concerns: Multimodal systems often process more sensitive personal information—faces, voices, personal documents—raising additional privacy and security considerations.
These challenges require ongoing research and careful system design to ensure multimodal AI is reliable, fair, and beneficial.
The Future of Multimodal Intelligence
Multimodal AI is rapidly evolving toward more sophisticated and seamless integration:
- Real-time multimodal conversation: AI systems that can naturally switch between text, voice, images, and other modalities within a single conversation flow.
- Embodied AI: Systems that combine multimodal understanding with physical presence—robots that can see, hear, speak, and interact with the physical world.
- Augmented reality integration: AI that can understand and augment real-world environments by combining visual perception with contextual knowledge.
- Personalized multimodal experiences: Systems that adapt their communication style and modality preferences to individual users and situations.
These advances point toward AI systems that communicate and create as naturally and flexibly as humans do.
Final Takeaways
Multimodal AI represents a fundamental shift from specialized, single-purpose systems toward AI that can understand and generate across the full spectrum of human communication modalities. By combining vision, language, audio, and video processing, these systems enable more natural, comprehensive, and accessible interactions.
Understanding multimodal capabilities helps explain why modern AI assistants feel increasingly natural and versatile—they're not just processing text but engaging with the rich, multifaceted ways humans actually communicate and solve problems. As these systems continue to improve, the boundary between human and AI communication styles will continue to blur, creating more intuitive and powerful collaborative experiences.