Traditionele taalmodellen zoals ChatGPT-3 hebben geen toegang tot realtime updates of informatie buiten hun trainingsdata. Dat betekent dat ze geen actuele nieuwsberichten, beurskoersen of privé-documenten kunnen ophalen. Hun kennis staat vast op het moment van training: krachtig, maar beperkt.
Retrieval-Augmented Generation (RAG) lost dit op door AI-systemen te verbinden met externe bronnen—publieke databanken, privébestanden of gespecialiseerde kennisbanken. In plaats van alleen op geheugen te vertrouwen, kan het model informatie opzoeken en integreren, waardoor een statische expert verandert in een dynamische bibliotheek die steeds groeit.
Het "Knowledge Cutoff" Probleem
Elk taalmodel heeft een knowledge cutoff—het moment waarop de trainingsdata ophoudt. Na die datum weet het niets meer over wereldgebeurtenissen, nieuwe ontdekkingen of veranderende situaties.
Dit leidt tot praktische problemen:
- Verouderde informatie: Een model getraind in 2023 kan vol vertrouwen zeggen dat een bepaalde CEO nog steeds een bedrijf leidt, terwijl die inmiddels is vertrokken.
- Ontbrekende context: Zonder recente informatie kan AI actuele gebeurtenissen, nieuwe producten of veranderende situaties niet begrijpen.
- Statische kennis: Informatie die vaak verandert—beurskoersen, weer, sportuitslagen—is meteen achterhaald.
- Domein gaten: Gespecialiseerde of private informatie die niet in de trainingsdata zat, is volledig ontoegankelijk.
Het resultaat: AI-systemen zijn geïnformeerd over hun trainingsperiode, maar blind voor alles wat erna kwam.
🗞️ Nieuwsvoorbeeld: Vraag je een model getraind vóór 2024 naar de Olympische Spelen van 2024, dan vertelt het over de geplande Spelen in Parijs, maar het kent de echte uitslagen, hoogtepunten of verrassingen niet.
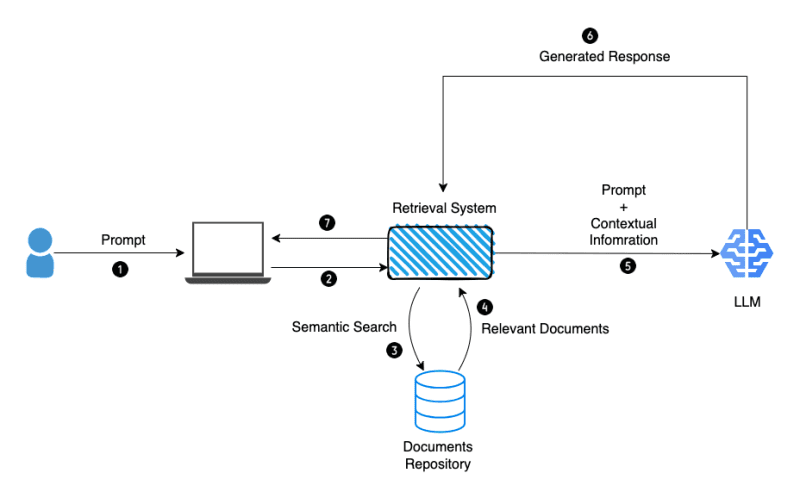
Hoe RAG Werkt: Het Retrievalproces
RAG-systemen combineren twee mogelijkheden: relevante informatie ophalen uit externe bronnen en antwoorden genereren die die informatie verwerken. Stap voor stap:
- Gebruikersprompt: Je dient je vraag of verzoek in.
- Semantische zoekopdracht: Het systeem zet je vraag om in een zoekquery en zoekt in externe databanken, documenten of kennisbanken.
- Document retrieval: Relevante documenten worden geïdentificeerd en opgehaald.
- Relevantie-filtering: Documenten worden gescoord en gerangschikt op basis van relevantie.
- Context-integratie: De meest relevante informatie wordt gecombineerd met je vraag en ingevoerd in het contextvenster van het taalmodel.
- Antwoordgeneratie: Het LLM genereert een antwoord met zowel zijn trainingskennis als de opgehaalde informatie.
Dit gebeurt in seconden en creëert de ervaring van een AI die “weet” over actuele of externe onderwerpen.
Typen Kennisbronnen
RAG-systemen kunnen verschillende soorten externe kennis aanspreken:
- Websearch: Realtime internetzoekopdrachten voor actuele informatie, nieuws en diverse perspectieven.
- Documentdatabanken: Bedrijfswikis, beleidsdocumenten en interne kennisbanken.
- Wetenschappelijke literatuur: Artikelen, onderzoeksdatabases en technische documentatie.
- Persoonlijke bestanden: Je eigen documenten, e-mails en notities.
- Gestructureerde databanken: Financiële gegevens, productcatalogi en andere gestructureerde data.
De sleutel is om de juiste bron te koppelen aan de vraag van de gebruiker.
De Vector Search Revolutie
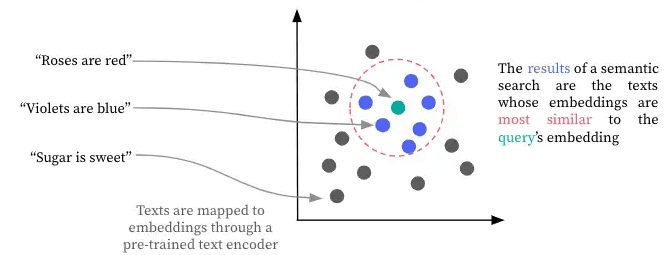
Traditionele keyword search mist vaak documenten die hetzelfde concept beschrijven met andere woorden. Moderne RAG-systemen gebruiken vector search, gebaseerd op embeddings (zie Hoofdstuk 5).
Embeddings plaatsen vergelijkbare woorden dicht bij elkaar in een hoog-dimensionale ruimte. Vector search past dit toe op documenten: teksten over verwante onderwerpen krijgen vergelijkbare representaties, zelfs met andere woordkeuze.
- Semantische gelijkenis: In plaats van exacte woorden, zoekt vector search naar dezelfde betekenis. Een zoekopdracht “car problems” kan documenten opleveren over “automotive issues” of “vehicle maintenance”.
- Contextueel begrip: “Apple” in een techdocument verwijst naar het bedrijf, in een voedingsartikel naar de vrucht.
- Cross-language: Vector embeddings kunnen betekenissen over talen heen vangen.
- Fuzzy matching: Ook bij spelfouten of alternatieve formuleringen vindt vector search relevante resultaten.
📊 Zoekvoorbeeld: Vraag je “Hoe doet ons bedrijf het financieel?”, dan vindt vector search documenten met termen als “quarterly earnings”, “revenue growth” en “fiscal performance”—ook al noemde je die zelf niet.
Uitdagingen bij RAG-Implementatie
RAG is krachtig, maar kent ook uitdagingen:
- Kwaliteit van informatie: Opgehaalde documenten kunnen verouderd, bevooroordeeld of foutief zijn.
- Relevantie-filtering: Niet alles wat wordt opgehaald is nuttig voor de vraag.
- Contextlimieten: De hoeveelheid info die kan worden verwerkt blijft beperkt door het contextvenster.
- Bronconflicten: Tegenstrijdige informatie uit verschillende bronnen moet worden verzoend of benoemd.
Dit vraagt zorgvuldig systeemontwerp en continue verfijning.
RAG in de Praktijk
RAG verandert hoe AI-assistenten werken in verschillende domeinen:
🏢 Bedrijfskennis: Medewerkers krijgen toegang tot interne documentatie en beleid verspreid over systemen.
📚 Juridisch: RAG zoekt door jurisprudentie, regelgeving en precedenten.
🏥 Zorg: Medische AI kan actuele richtlijnen, onderzoek en medicijninformatie raadplegen.
Elke toepassing vereist zorgvuldig geselecteerde bronnen en afgestemde retrievalmechanismen.
De Hybride Aanpak: Parametrische + Opgehaalde Kennis
Moderne AI combineert interne en externe kennis:
- Parametrische kennis: Wat tijdens training is geleerd, opgeslagen in modelparameters.
- Opgehaalde kennis: Recente, specifieke of gespecialiseerde informatie uit externe bronnen.
- Dynamische integratie: Het systeem leert wanneer interne kennis volstaat en wanneer retrieval nodig is.
🔍 Integratievoorbeeld: Vraag je “Wat zijn de laatste ontwikkelingen in quantum computing?”, dan gebruikt de AI zijn parametrische kennis om de basis uit te leggen, maar retrieval om actuele doorbraken of persberichten te benoemen.
De Toekomst van RAG: Naar Realtime Kennis
RAG ontwikkelt zich snel richting realtime en meerlagige kennis:
- Continue learning: Systemen die continu updaten in plaats van periodieke trainingen.
- Multi-modale RAG: Integratie van tekst, beeld, audio en video.
- Gepersonaliseerde kennis: Aangepast aan de voorkeuren en context van individuele gebruikers.
- Realtime synthese: Meerdere bronnen direct combineren om complexe vragen te beantwoorden.
Dit wijst op AI-systemen die steeds actueler en deskundiger aanvoelen.
Belangrijkste Inzichten
RAG transformeert statische taalmodellen in dynamische kennissystemen. Door redeneringsvermogen te combineren met actuele en externe informatie, ontstaan AI-assistenten die zowel slim als up-to-date zijn.
Het verklaart waarom sommige AI’s vragen over recente gebeurtenissen of je eigen documenten kunnen beantwoorden, terwijl andere dat niet kunnen. Naarmate RAG verbetert, zal de grens tussen wat AI “weet” en wat het kan “opzoeken” steeds meer vervagen.